Applying NLP and Entity Extraction To The Russian Twitter Troll Tweets In Neo4j (and more Python!)
William Lyon / November 15, 2017
9 min read •
Russian Twitter Troll Tweets
Previously, we explored how to scrape tweets from Internet Archive that have been removed from Twitter.com and the Twitter API as a result of the US House Intelligence Committee's investigation into Russia's involvement in influencing the 2016 election through social media, largely by spreading fake news.
These accounts were identified by Twitter as connected to Russia's Internet Research Agency, a company believed to have been involved in spreading fake news in an attempt to influence the US election, however Twitter has removed all data related to these accounts.
Our previous post focused on scraping Internet Archive to retrieve the data and import into Neo4j. We also looked at some Cypher queries we could use to analyze the data. In this post we make use of a natural language processing technique called entity extraction to enrich our graph data model and help us explore the dataset of Russian Twitter Troll Tweets. For example, can we try to see what people, places, and organizations these accounts were tweeting about in the months leading up to the 2016 election?
Named Entity Recognition
According to Wikipedia:
Named-entity recognition (NER) (also known as entity identification, entity chunking and entity extraction) is a subtask of information extraction that seeks to locate and classify named entities in text into pre-defined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc.
Entity extraction is an important task in natural language processing and information extraction and can be used to help make sense of large bodies of text.
Entity Extraction With Polyglot#
There are several NLP libraries and services available (such as Stanford CoreNLP, IBM's AlchemyAPI, Thomson Reuters' Open Calais) that offer entity extraction. One tool that I like is Polyglot, a Python library and command line tool for NLP. Polyglot supports many different languages (up to 165 for some NLP tasks) and a wide range of NLP features including language detection, sentiment analysis, part of speech tagging, and word embeddings.
In this post we'll make use of Polyglot's entity extraction functionality to find entities mentioned in the tweets in our Russian Twitter Troll tweet data.
Other entity extraction tools use supervised learning approaches that require human labeled training data. Polyglot however uses link structure from Wikipedia and Freebase that results in a language agnostic technique for entity extraction. You can read more about their technique in this paper.
Installing Polyglot#
From looking at some issues online it seems many folks struggle with installing Polyglot, especially on MacOS. These are the steps I used to install Polyglot with the Anaconda Python distribution on Ubuntu 16.04, including Jupyter, thanks to this gist.
conda create -n icutestenv python=3.5.2 --no-deps -y
source activate icutestenv
conda install -c ccordoba12 icu=54.1 -y
conda install ipython numpy scipy jupyter notebook -y
python -m ipykernel install --user
easy_install pyicu
pip install morfessor
pip install pycld2
pip install polyglot
Applying Entity Extraction To The Russian Twitter Troll Dataset
Our approach will be to use the Python driver for Neo4j to retrieve all the tweet text in our dataset from Neo4j, run the Polyglot entity extraction algorithm on the text of each tweet, saving the tweet text, tweet id, and extracted entities to a JSON file that we can then use to update the Neo4j graph, extending the datamodel to connect Tweet nodes to new Person, Location, and Organization nodes as identified by Polyglot.
Running Polyglot Entity Extraction#
Polyglot entity extraction works by taking a piece of text (tweets in our case), and annotating (or tagging) the text where it recognizes named entities.
Polyglot can recognize three types of entities:
- Locations (Tag: I-LOC)
- cities, countries, regions, continents, neighborhoods, etc.
- Organizations (Tag: I-ORG):
- companies, schools, newspapers, political parties, etc.
- Persons (Tag: I-PER):
- politicians, celebrities, authors, etc.
Here's a simple example:
# simple Polyglot entity extraction example
from polyglot.text import Text
blob = Text('@realDonaldTrump "Hillary Clinton has zero record to run on - unless you call corruption positive.." - @IngrahamAngle')
blob.entities
And we can see that Polyglot recognized "Hillary Clinton" as a Person entity:
[I-PER(['Hillary', 'Clinton'])]
Note that Polyglot did not tag either of the two Twitter screen names, @realDonaldTrump or @IngramAngle as entities. Since our data has Twitter mentions we can infer these already.
Retrieving Tweet Data From Neo4j#
We start with the Neo4j database that we built from scraped tweets in the previous post. We want to query that database for all tweets, retrieving the text of the tweet and the tweet id. We create a Python dict for each tweet that contains the id and text and then append each tweet dict to a list:
from neo4j.v1 import GraphDatabase
driver = GraphDatabase.driver("bolt://localhost:7687")
with driver.session() as session:
results = session.run("MATCH (t:Tweet) RETURN t.text AS text, t.tweet_id AS tweet_id")
tweetObjArr = []
for r in results:
tweetObj = {}
tweetObj['id'] = r['tweet_id']
tweetObj['text'] = r['text']
tweetObjArr.append(tweetObj)
Next, we iterate through each tweet dict in the array and run the Polyglot entity extaction algorithm for each tweet. We create a new dict, including any tagged entities and append those to a new array:
entityArr = []
for t in tweetObjArr:
try:
parsedTweet = {}
parsedTweet['id'] = t['id']
parsedTweet['text'] = t['text']
blob = Text(t['text'])
entities = blob.entities
parsedTweet['entities'] = []
for e in entities:
eobj = {}
eobj['tag'] = e.tag
eobj['entity'] = e
parsedTweet['entities'].append(eobj)
if len(parsedTweet['entities']) > 0:
entityArr.append(parsedTweet)
except:
pass
Note that we could write this in a more pythonic list comprehension, but I think this version is better for seeing what exactly is going on.
Here's an example of what we have at this point:
{
"entities": [
{
"entity": [
"Republicans"
],
"tag": "I-ORG"
},
{
"entity": [
"FBI"
],
"tag": "I-ORG"
},
{
"entity": [
"Clinton"
],
"tag": "I-PER"
}
],
"id": 784163886547230720,
"text": "RT @OffGridInThePNW: Republicans blast FBI for 'astonishing' agreement to destroy Clinton aides' laptops | https://t.co/cwEUtK9i9V"
}
Next, we save this array of entities and tweets to a json file that we'll use in the next step to import into Neo4j:
import json
with open('parsed_tweets.json', 'w') as f:
json.dump(entityArr, f, ensure_ascii=False, sort_keys=True, indent=4)
{'entities': [{'entity': I-PER(['Hillary', 'Clinton']), 'tag': 'I-PER'}],
'id': 773585101489922048,
'text': '@realDonaldTrump "Hillary Clinton has zero record to run on - unless you call corruption positive.." - @IngrahamAngle'}
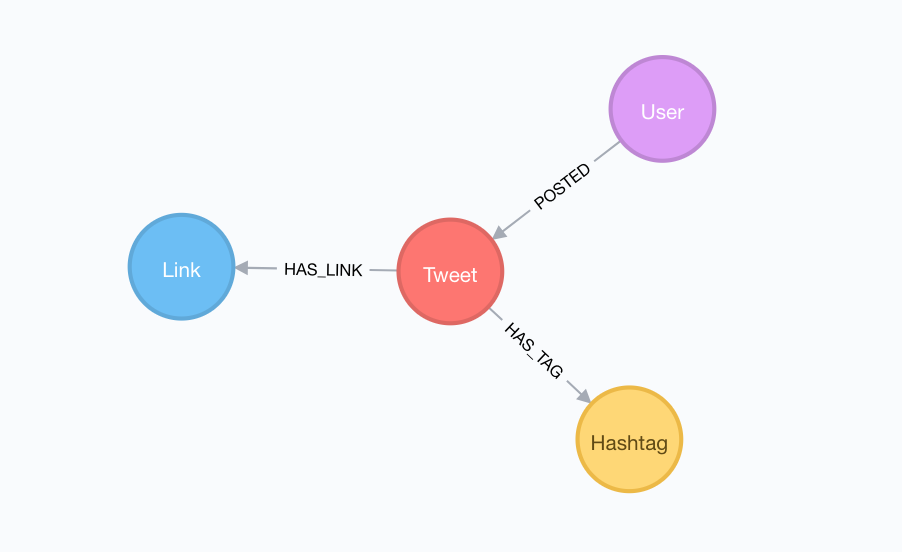
Importing Extracted Entities Into Neo4j#
So far our datamodel looks like this:
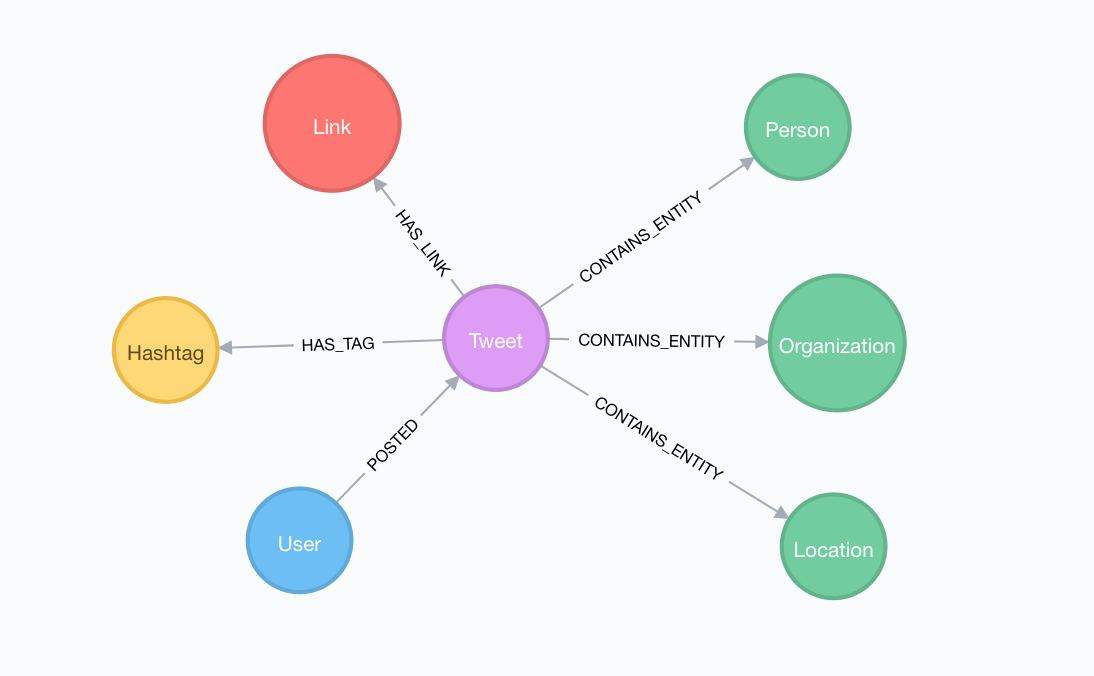
What we want to do is extend the data model to include Person, Location, and Organization nodes, connected to any tweets that contain references to these entities:
From the previous step, we have a json file of tweet text, tweet id, and extracted entities:
{'entities': [{'entity': ['California'], 'tag': 'I-LOC'},
{'entity': ['Cleveland'], 'tag': 'I-LOC'},
{'entity': ['Nicholas', 'Rowe'], 'tag': 'I-PER'}],
'id': '669554555835682816',
'text': 'California man killed in Cleveland was shot in the head and back: '
'Nicholas Rowe was identified as the man found dead Nov. 20 b... '
'#crime'}
First, we execute three Cypher queries to add uniqueness constraints to our database. The uniqueness constaints allow us to assert that no duplicate nodes will be created. For example, we only want one node with the label Location and name property California to represent the state of California. Any tweets that contain "California" should all have a relationship to the canonical "California" node. Uniqueness constraints give us this guarantee. Uniqueness constraints also create an index, which will speed our import significantly.
with driver.session() as session:
session.run('CREATE CONSTRAINT ON (p:Person) ASSERT p.name IS UNIQUE;')
session.run('CREATE CONSTRAINT ON (l:Location) ASSERT l.name IS UNIQUE;')
session.run('CREATE CONSTRAINT ON (o:Organization) ASSERT o.name IS UNIQUE;')
Next, we load our json file that contains tweets and entities:
with open("parsed_tweets.json") as f:
parsed_tweets = json.load(f)
And define a Cypher query that will take this array of tweets and entities, iterate through them and update the graph, creating new Person, Organization, and Location nodes and creating relationships to any tweets that contains these entities:
entity_import_query = '''
WITH $parsedTweets AS parsedTweets
UNWIND parsedTweets AS parsedTweet
MATCH (t:Tweet) WHERE t.tweet_id = parsedTweet.id
FOREACH(entity IN parsedTweet.entities |
// Person
FOREACH(_ IN CASE WHEN entity.tag = 'I-PER' THEN [1] ELSE [] END |
MERGE (p:Person {name: reduce(s = "", x IN entity.entity | s + x + " ")}) //FIXME: trailing space
MERGE (p)<-[:CONTAINS_ENTITY]-(t)
)
// Organization
FOREACH(_ IN CASE WHEN entity.tag = 'I-ORG' THEN [1] ELSE [] END |
MERGE (o:Organization {name: reduce(s = "", x IN entity.entity | s + x + " ")}) //FIXME: trailing space
MERGE (o)<-[:CONTAINS_ENTITY]-(t)
)
// Location
FOREACH(_ IN CASE WHEN entity.tag = 'I-LOC' THEN [1] ELSE [] END |
MERGE (l:Location {name: reduce(s = "", x IN entity.entity | s + x + " ")}) // FIXME: trailing space
MERGE (l)<-[:CONTAINS_ENTITY]-(t)
)
)
'''
Note that we make use of the FOREACH( _ IN CASE WHEN ... THEN [1] ELSE [] END | ... ) trick for handling conditionals.
Finally, we use the Neo4j Python driver to run our import query, passing in the array of dicts as a parameter:
with driver.session() as session:
session.run(entity_import_query, parsedTweets=parsed_tweets)
Making sense of our extracted entities#
Now that we've enriched our graph model we can answer a few more interesting questions of our Russia Twitter Troll dataset.
Most frequently mentioned entities#
// Most frequently mentioned Person entities
MATCH (t:Tweet)-[:CONTAINS_ENTITY]->(p:Person)
RETURN p.name AS name, COUNT(*) AS num ORDER BY num DESC LIMIT 10
╒══════════════════╤═════╕
│"name" │"num"│
╞══════════════════╪═════╡
│"Trump " │22 │
├──────────────────┼─────┤
│"… " │18 │
├──────────────────┼─────┤
│"Obama " │15 │
├──────────────────┼─────┤
│"Clinton " │12 │
├──────────────────┼─────┤
│"Hillary " │12 │
├──────────────────┼─────┤
│"sanders " │7 │
├──────────────────┼─────┤
│"Bernie Sanders " │6 │
├──────────────────┼─────┤
│"Donald Trump " │6 │
├──────────────────┼─────┤
│"pic.twitter.com "│6 │
├──────────────────┼─────┤
│"Hillary Clinton "│6 │
└──────────────────┴─────┘
// Most frequently mentioned Location entities
MATCH (t:Tweet)-[:CONTAINS_ENTITY]->(l:Location)
RETURN l.name AS name, COUNT(*) AS num ORDER BY num DESC LIMIT 10
╒══════════════╤═════╕
│"name" │"num"│
╞══════════════╪═════╡
│"Louisiana " │13 │
├──────────────┼─────┤
│"Chicago " │13 │
├──────────────┼─────┤
│"Cleveland " │11 │
├──────────────┼─────┤
│"baltimore " │9 │
├──────────────┼─────┤
│"Miami " │8 │
├──────────────┼─────┤
│"Ohio " │6 │
├──────────────┼─────┤
│"California " │6 │
├──────────────┼─────┤
│"Iraq " │6 │
├──────────────┼─────┤
│"Westboro " │5 │
├──────────────┼─────┤
│"New Orleans "│5 │
└──────────────┴─────┘
Exploring Tweets Around Certain Entities#
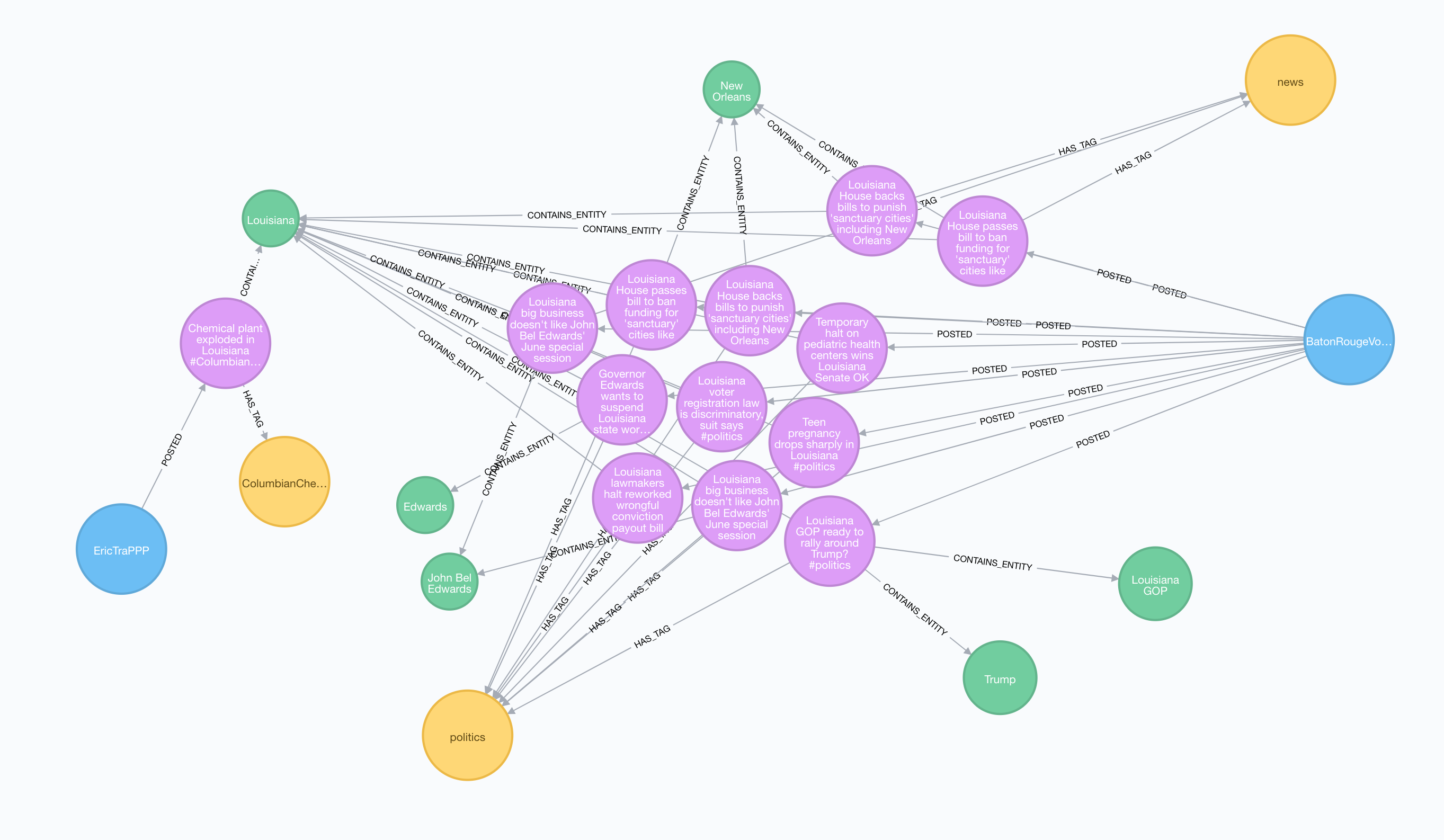
// Tweets, hashtags, and entities around Louisiana
MATCH (u:User)-[:POSTED]->(t:Tweet)-[:CONTAINS_ENTITY]->(l:Location {name: "Louisiana "} )
OPTIONAL MATCH (t)-[:HAS_TAG]->(ht:Hashtag)
OPTIONAL MATCH (t)-[:CONTAINS_ENTITY]->(e)
RETURN *
You can find the code for this project on Github, in this Jupyter notebook:
Subscribe To Will's Newsletter
Want to know when the next blog post or video is published? Subscribe now!