Combining The BuzzFeed Trumpworld Graph with Government Contracting Data in Neo4j
William Lyon / January 30, 2017
12 min read •

One of the powers of working with graph databases is the ability to combine disparate datasets and query across them. Today we'll look at how we can combine the BuzzFeed Trumpworld graph with data about federal government contracts from USASpending.gov, allowing us to examine any government contracts that were awarded to organizations that appear in Trumpworld.
The BuzzFeed Trumpworld Graph
A few weeks ago BuzzFeed released a dataset of people and organizations with connections to Donald Trump, calling it the Trumpworld dataset. They wanted to make this data available to the public as part of their work, and also solicit feedback from the community to help find missing connections.
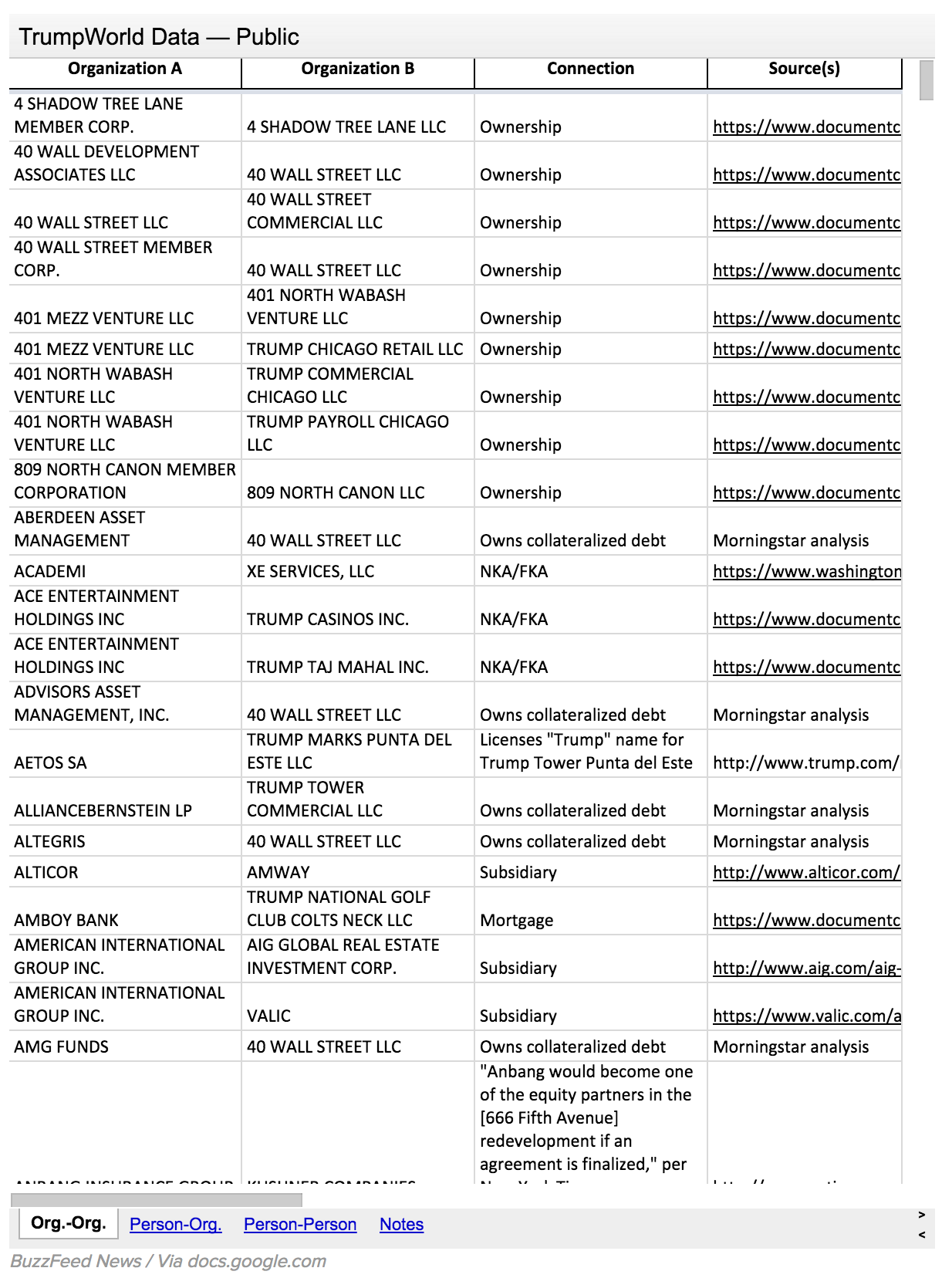 The BuzzFeed Trumpworld dataset. People, organizations, and their connections around Donald Trump.
The BuzzFeed Trumpworld dataset. People, organizations, and their connections around Donald Trump.
My colleague Michael Hunger wrote import scripts for loading this data into Neo4j. He also wrote an excellent blog post about working with the Trumpworld Graph in Neo4j. If you haven't read it yet, start there because this post takes his work and builds on it by integrating data on US government contracts.
By working with this data in Neo4j we can write queries, such as "Show me the second degree network of Jared Kushner":
MATCH network = (:Person {name:"JARED KUSHNER"})-[*..2]-()
RETURN network
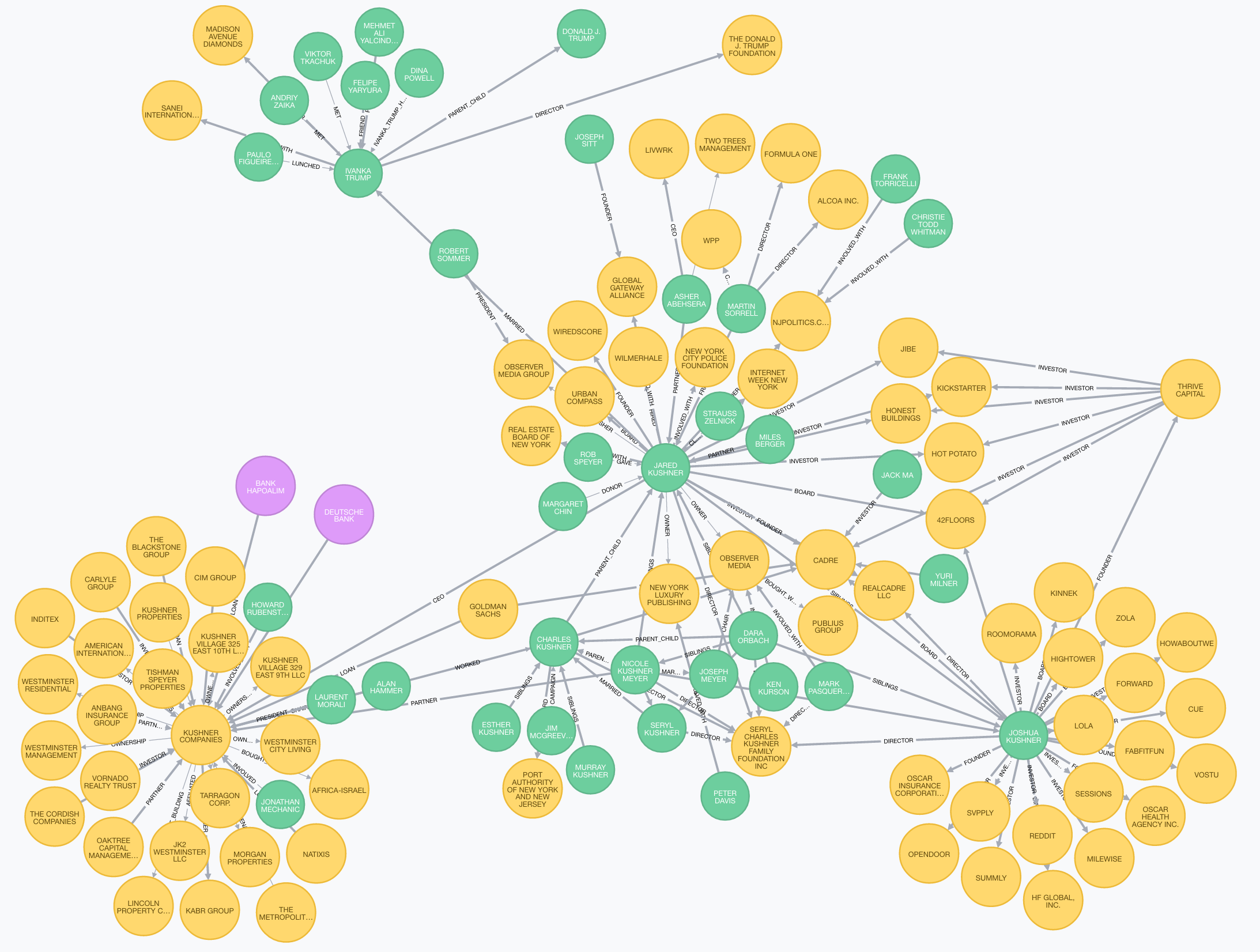 The second degree network of Jared Kushner.
The second degree network of Jared Kushner.
Adding US Government Contracting Data - USASpending.gov
Data on recipients of federal government contracts is available online, at USASpending.gov.
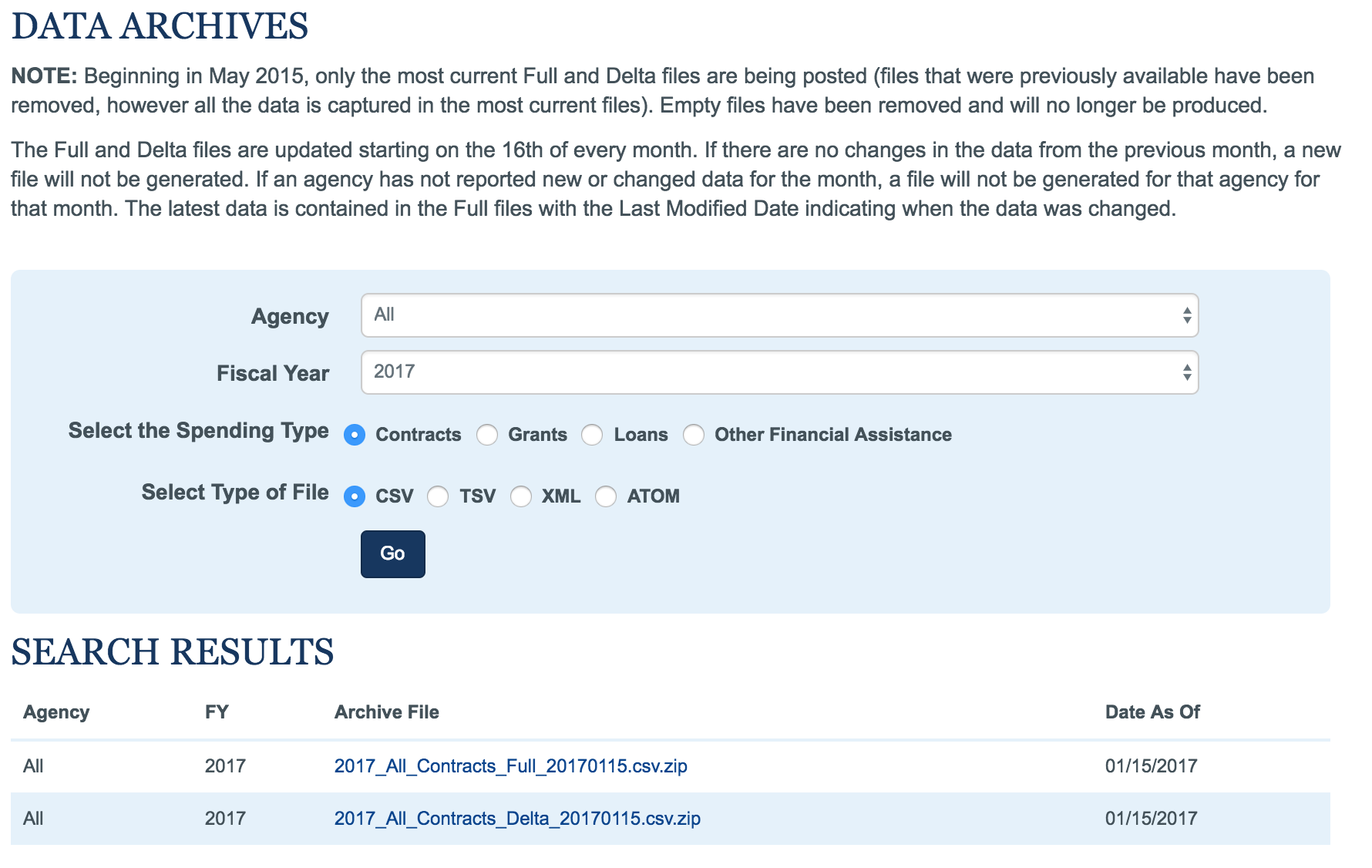 Data download page for USASpending.gov. I started with contracts issued by all agencies for the 2016 fiscal year.
Data download page for USASpending.gov. I started with contracts issued by all agencies for the 2016 fiscal year.
We may need to reference the data dictionary for USASpending.gov
The Data#
Each row in the CSV file represents a contract that has been awarded to an organization, issued by a federal government agency (actually each row represents a transaction, and we could have multiple transactions per contract, but let's simplify our thinking and just think of each row as a contract).
Looking at the data dictionary we can see that each row has a lot of fields (225 actually!), so there is a lot of information encoded in each row. We are mainly interested in:
- What organization was awarded the contract?
- What is the parent organization of the awardee (is it a subsidiary)?
- The amount of the contract
- The agency issuing the contract
- The purpose of the contract
We can use Cypher's LOAD CSV functionality to exaimine the first few rows of the CSV file and return specifically the columns we are interested in:
// Load the contractors CSV file and return the first 5 rows
// but only the columns we're interested in
LOAD CSV WITH HEADERS
FROM "file:///2016_All_Contracts_Full_20170115.csv" AS row
WITH row LIMIT 5
RETURN row.piid AS piid,
row.fiscal_year AS fiscal_year,
row.vendorname AS vendor_name,
row.mod_parent AS parent_org,
row.dollarsobligated AS amount,
row.contractingofficeagencyid AS agency,
row.productorservicecode AS purpose
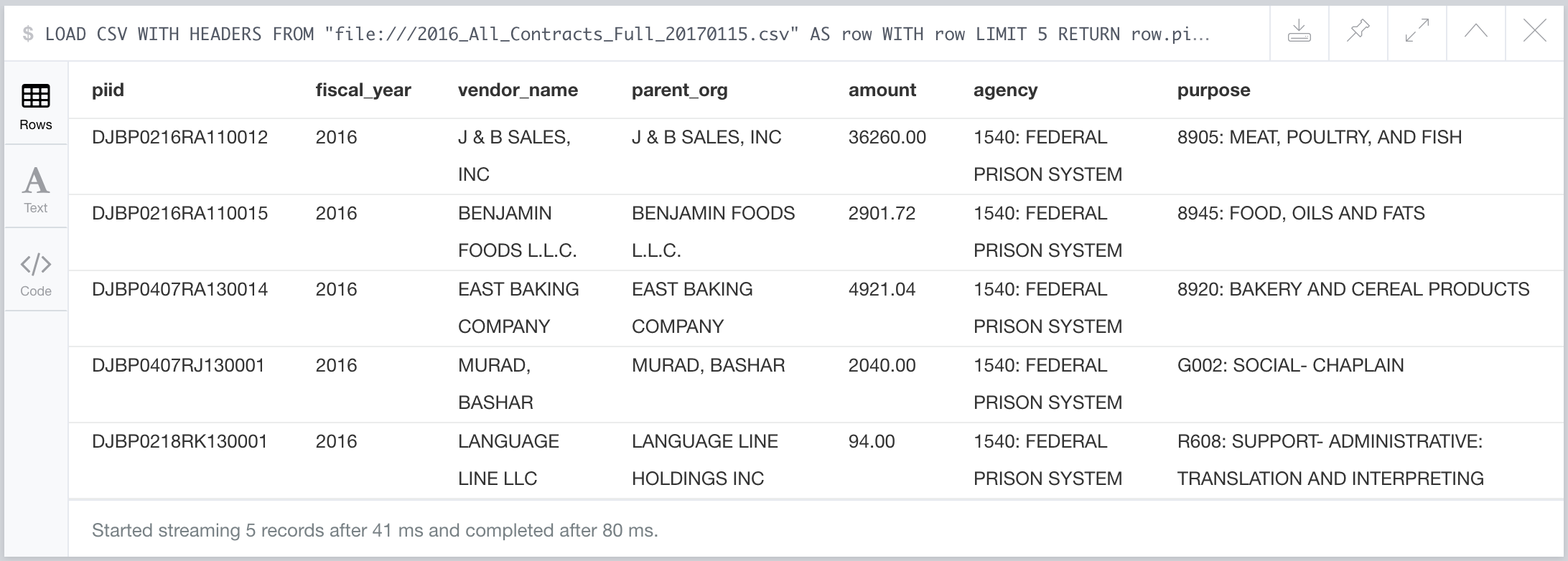
I found a few rows where the quote escaping wasn't quite right, and the Neo4j CSV parser wasn't able to parse the row correctly. I removed any of these rows using sed. For example:
$sed -i '4671792 d' 2016_All_Contracts_Full_20170115.csv
So here we can see some contracts that were issued by the Federal Prison System to various vendors. Now we could certainly import the entire dataset into Neo4j and run some interesting queries for analysis, but we're specifically interested in finding contracts that were awarded to vendors that appear in the Trumpworld dataset. Let's see if we can find any. To do this we need to MATCH on Organization nodes where the name property of the organization is equal to the vendorname column in the CSV file. We have to look through 5000 rows before we find a match:
LOAD CSV WITH HEADERS FROM
"file:///2016_All_Contracts_Full_20170115.csv" AS row
WITH row LIMIT 50000
MATCH (o:Organization) WHERE o.name = row.vendorname
RETURN row.piid AS piid,
row.fiscal_year AS fiscal_year,
row.vendorname AS vendor_name,
row.mod_parent AS parent_org,
row.dollarsobligated AS amount,
row.contractingofficeagencyid AS agency,
row.productorservicecode AS purpose
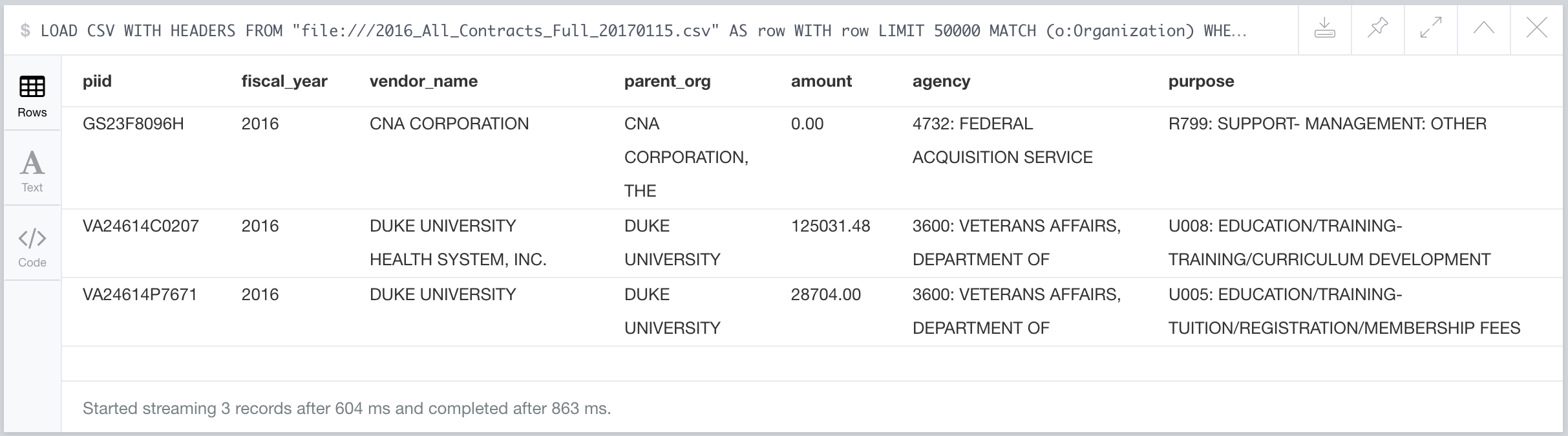
Here we see Duke University showing up as a vendor. This means that Duke University must be in the Trumpworld data. How is Duke University connected to Donald Trump?
MATCH p=(duke:Organization)-[*1..5]-(donald:Person)
WHERE duke.name = "DUKE UNIVERSITY" AND
donald.name = "DONALD J. TRUMP"
RETURN p LIMIT 1
 How is Donald Trump connected to Duke University?
How is Donald Trump connected to Duke University?
We can see that in this case the vendor_name and parent_org values are the same. This means that Duke University isn't part of larger organization. Parent company information is provided by Dun & Bradstreet. We are also interested in finding contracts that were awarded to subsidiaries of companies in Trumpworld, as this would also help us identify potential conflicts of interest. To find these contracts (one that was awarded to a vendor where the vendor is a subsidiary of a company that appears in Trumpworld) we'll need to match on Organization nodes where the name property is equal to the parent_org column and where the vendor_name is not equal to parent_org. To find examples of these we need to look through a few more rows - the first 50000 (but don't worry there are more than 4 million rows in this CSV file!):
LOAD CSV WITH HEADERS
FROM "file:///2016_All_Contracts_Full_20170115.csv" AS row
WITH row LIMIT 50000
MATCH (o:Organization)
WHERE o.name = row.mod_parent
AND NOT row.mod_parent = row.vendorname
RETURN row.piid AS piid,
row.fiscal_year AS fiscal_year,
row.vendorname AS vendor_name,
row.mod_parent AS parent_org,
row.dollarsobligated AS amount,
row.contractingofficeagencyid AS agency,
row.productorservicecode AS purpose
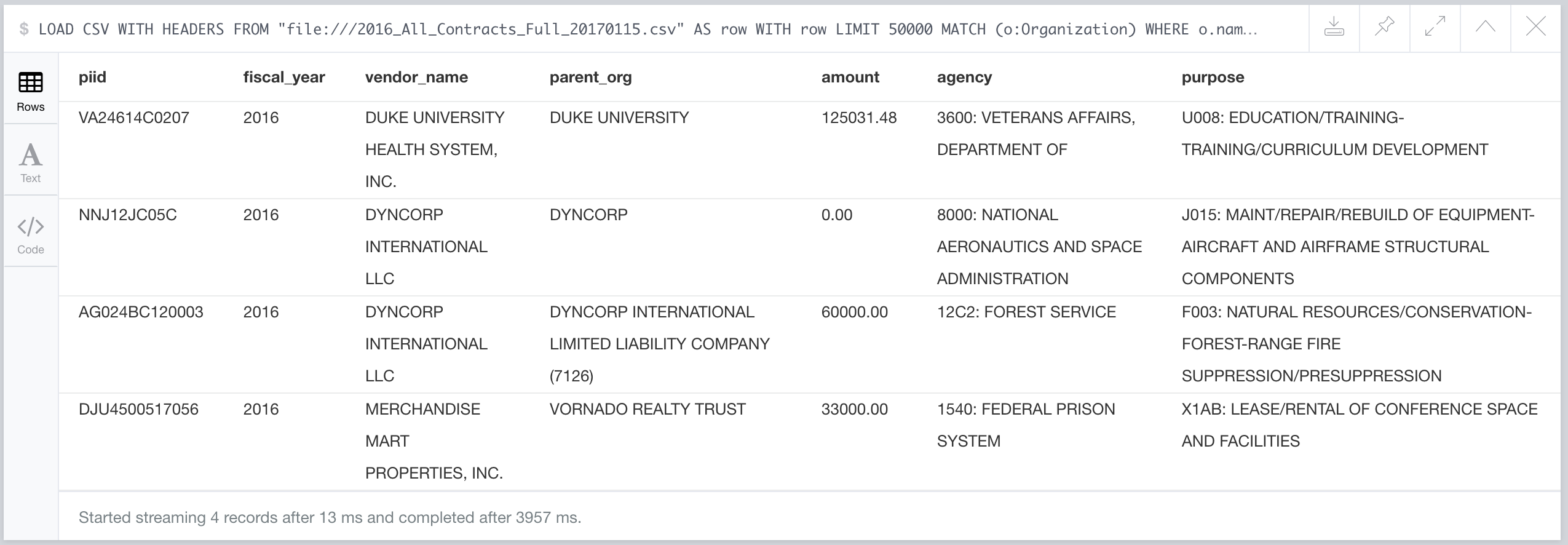
The Labeled Property Graph Model#
How might we model this contract data as a graph? Let's examine the third contract in the table above:

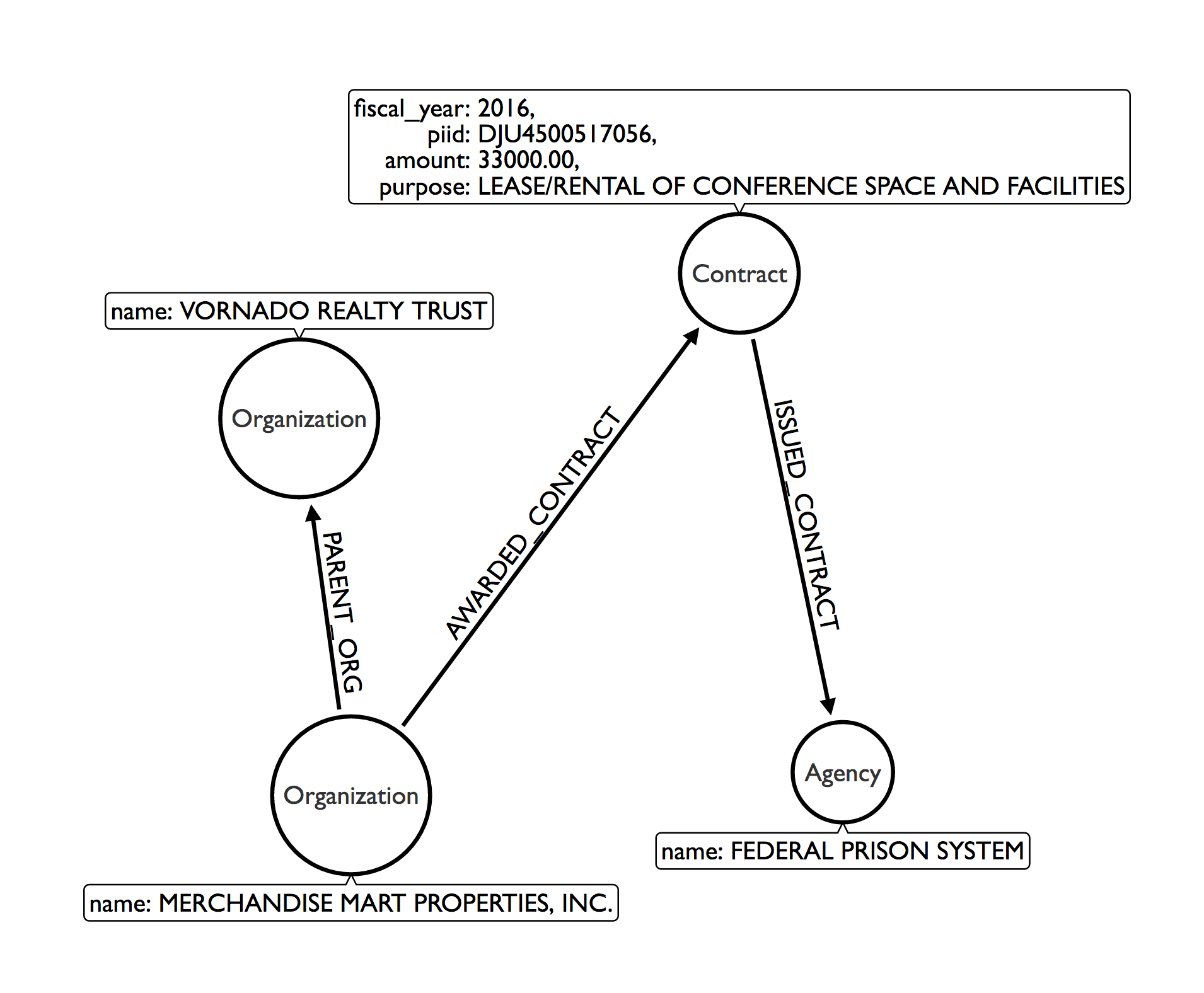 How should we model government contracts in Neo4j?
How should we model government contracts in Neo4j?
The entities we want to model are Organization, Contract, and government Agency.
Note that we have an overlap on Organization, which allows us to combine these two datasets and query across them.
Loading The Data#
Now we're ready to import the data into the Trumpworld graph. We'll end running two import queries:
First, where the vendor of the contract appears as an organization in Trumpworld
LOAD CSV WITH HEADERS
FROM "file:///2016_All_Contracts_Full_20170115.csv" AS row
MATCH (o:Organization) WHERE o.name = row.vendorname
WITH o,row.piid AS piid,
row.fiscal_year AS fiscal_year,
row.vendorname AS vendor_name,
row.mod_parent AS parent_org,
toFloat(row.dollarsobligated) AS amount,
substring(row.contractingofficeagencyid, 6) AS agency,
row.productorservicecode AS purpose
MERGE (a:Agency {name: agency})
MERGE (c:Contract {piid: piid})
ON CREATE SET c.amount = amount,
c.purpose = purpose,
c.fiscal_year = fiscal_year
// sum the transactions per contract
ON MATCH SET c.amount = c.amount + amount
MERGE (a)-[:ISSUED_CONTRACT]->(c)
MERGE (c)<-[:AWARDED_CONTRACT]-(o)
Then, a second query for loading contracts where the vendor's parent company appears as an organization in Trumpworld
LOAD CSV WITH HEADERS
FROM "file:///2016_All_Contracts_Full_20170115.csv" AS row
MATCH (parent:Organization)
WHERE parent.name = row.mod_parent
AND NOT row.mod_parent = row.vendorname
WITH parent, row.piid AS piid, row.fiscal_year AS fiscal_year,
row.vendorname AS vendor_name, row.mod_parent AS parent_org,
toFloat(row.dollarsobligated) AS amount,
substring(row.contractingofficeagencyid, 6) AS agency,
row.productorservicecode AS purpose
MERGE (vo:Organization {name: vendor_name})
MERGE (a:Agency {name: agency})
MERGE (c:Contract {piid: piid})
ON CREATE SET c.amount = amount,
c.purpose = purpose,
c.fiscal_year = fiscal_year
// sum the transactions per contract
ON MATCH SET c.amount = c.amount + amount
MERGE (a)-[:ISSUED_CONTRACT]->(c)
MERGE (c)<-[:AWARDED_CONTRACT]-(vo)
MERGE (parent)<-[:PARENT_ORG]-(vo)
Analyzing Trumpworld + USASpending#
Now that we've imported the USASpending data, let's take a look at the Merchandise Mart Properties, Inc contract. Since this is the Trumpworld graph, a logical question we might ask is "What is the connection from this contract to Donald Trump?". We can do this using the shortestPath function in Cypher:
MATCH (c:Contract {piid: "DJU4500517056"})
MATCH (c)<-[:ISSUED_CONTRACT]-(a:Agency)
MATCH (donald:Person {name: "DONALD J. TRUMP"})
MATCH p=shortestPath( (donald)-[*]-(c) )
RETURN *
The shortest path from a specific contract to Donald Trump.
Let's digest the result of this query. This graph visualization is showing us a contract awarded by the Federal Prison System for the lease of facilities that was awarded to a real estate company whose parent company is an investor in a company whose CEO is the son-in-law (and close advisor) of Donald Trump.
Why is this interesting? Is this a potential conflict of interest? I don't know, but I think it's pretty cool that we can find these kind of connectons using Neo4j and Cypher!
Of course, this is just one shortest path, there may be others. Let's find all shortest paths connecting this contract to Donald Trump:
MATCH (c:Contract {piid: "DJU4500517056"})
MATCH (c)<-[:ISSUED_CONTRACT]-(a:Agency)
MATCH (donald:Person {name: "DONALD J. TRUMP"})
MATCH p=allShortestPaths( (donald)-[*]-(c) )
RETURN *
 ALL shortest paths from a specific contract to Donald Trump.
ALL shortest paths from a specific contract to Donald Trump.
If we expand the length of the path a bit we can see a few more potentially interesting connections:
MATCH (c:Contract {piid: "DJU4500517056"})
MATCH (c)<-[:ISSUED_CONTRACT]-(a:Agency)
MATCH (donald:Person {name: "DONALD J. TRUMP"})
MATCH p=( (donald)-[*1..6]-(c) )
RETURN *
 ALL shortest paths from a specific contract to Donald Trump.
ALL shortest paths from a specific contract to Donald Trump.
Cabinet Nominees#
What connections do Trump's cabinet nominees have to contract vendors and parent companies of contract vendors?
MATCH (donald:Person {name: "DONALD J. TRUMP"})<-[r:NOMINEE]-(cabinet:Person)
MATCH p=(cabinet)--(o:Organization)-[*1..2]-(c:Contract)--(a:Agency)
RETURN *
 Connections from Trump's cabinet nominees to government contracts.
Connections from Trump's cabinet nominees to government contracts.
Let's take a closer look at the connection between some specific cabinet nominees to government contracts.
Rex Tillerson
Rex Tillerson is Trump's nominee for Secretary of State. He is also the former CEO and chairman of Exxon Mobil. Let's explore his connections in Trumpworld.
MATCH (p:Person {name:"REX TILLERSON"})--(o:Organization {name: "EXXON MOBIL CORPORATION"}),
path=(o)-[*1..2]-(c:Contract)--(a:Agency)
RETURN *
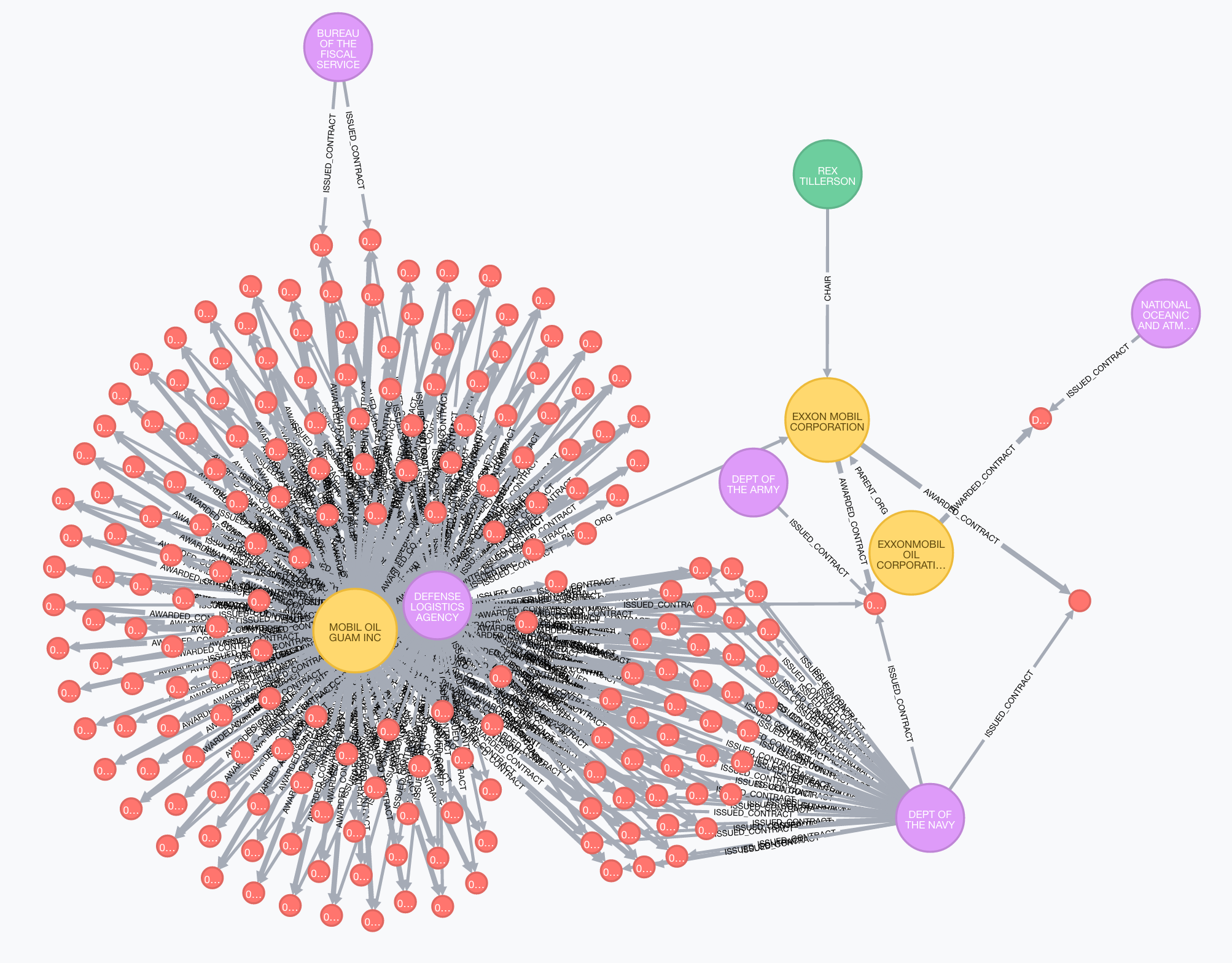 Connections from Rex Tillerson to government contracts, through Exxon Mobil.
Connections from Rex Tillerson to government contracts, through Exxon Mobil.
We can see that Exxon Mobil itself was only awarded two contracts, one from the Department of the Army and another from the Department of the Navy. However, because we are modeling parent companies as well we can see that a subsidiary of Exxon Mobil (Mobil Oil Guam Inc) has been awarded significant contracts from the Department of the Navy and the Defense Logistics Agency.
James Mattis
James Mattis is Trump's nominee for Secretary of Defense.
MATCH (p:Person {name:"JAMES MATTIS"})--(o:Organization),
path=(o)-[*1..2]-(c:Contract)--(a:Agency)
RETURN *
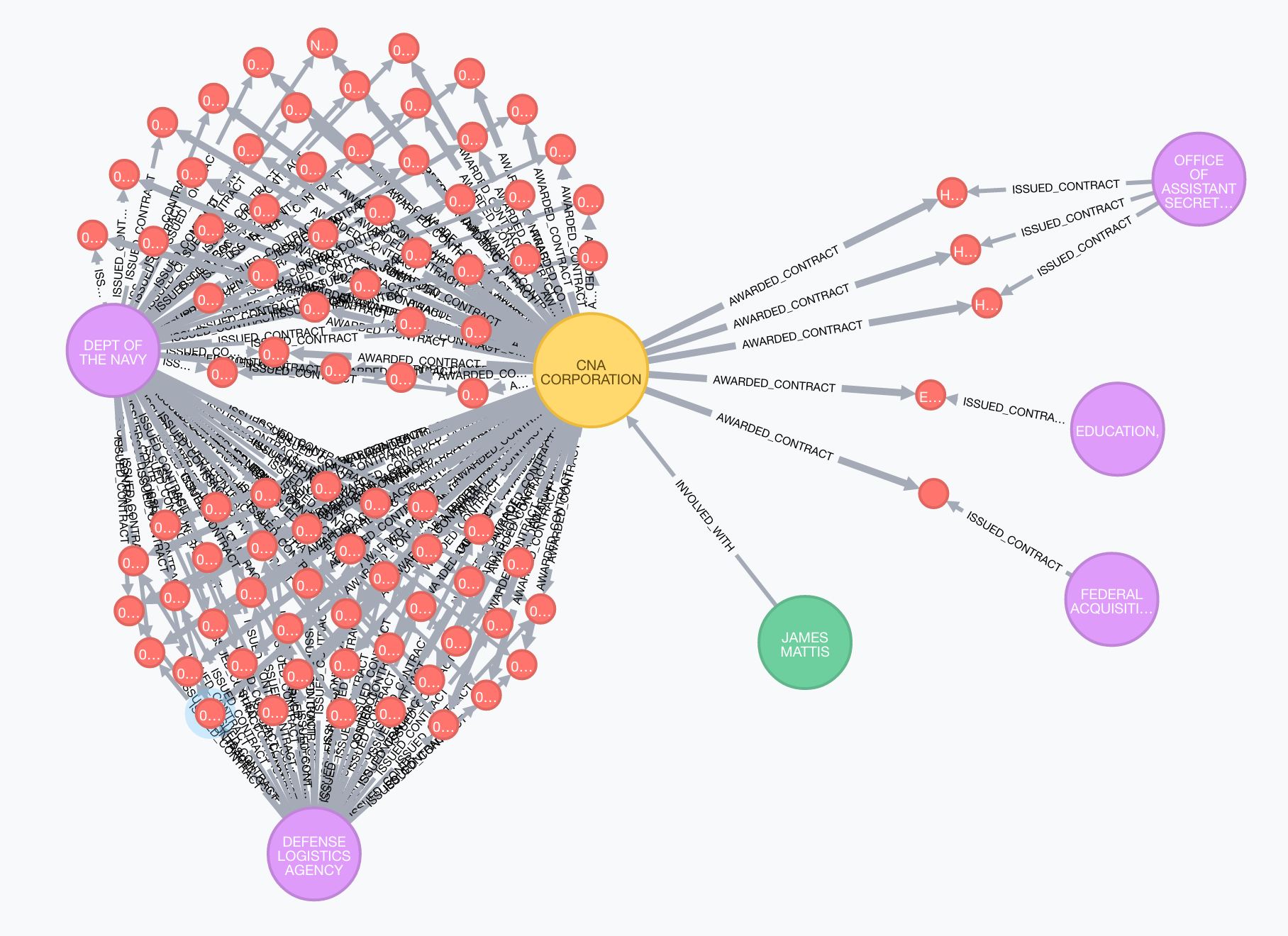 James Mattis has a direct connection to a company that is a vendor for several government contracts issued by departments that he oversees as Secretary of Defense.
James Mattis has a direct connection to a company that is a vendor for several government contracts issued by departments that he oversees as Secretary of Defense.
Connections to Trump#
Are there any direct connections from Trump to Organizations receiving government contracts?
MATCH (p:Person) WHERE p.name CONTAINS "DONALD J. TRUMP"
MATCH (p)-[]-(o:Organization)-[:AWARDED_CONTRACT]->(c:Contract),
(c)<-[:ISSUED_CONTRACT]-(a:Agency)
RETURN *
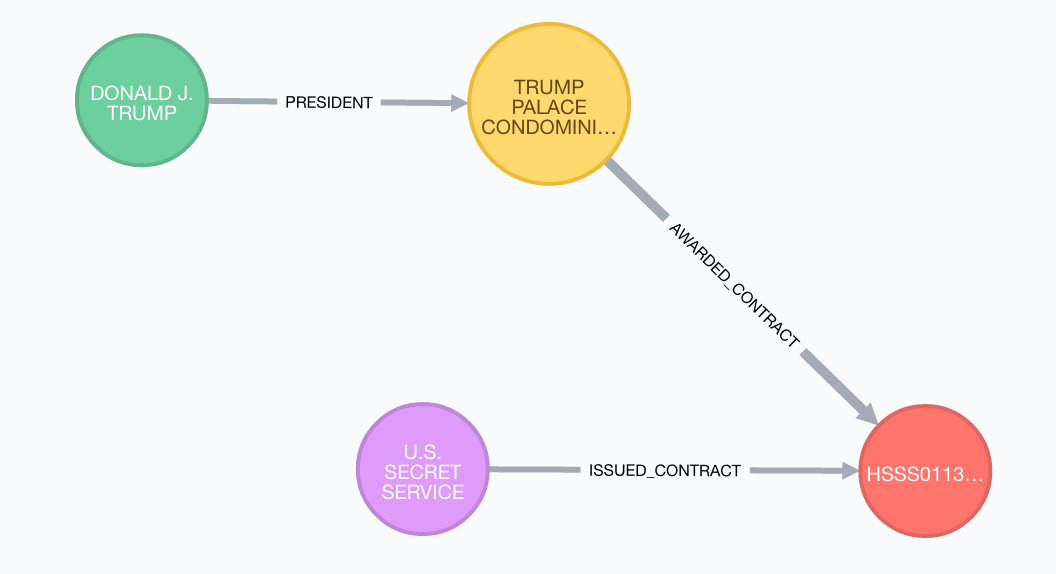 A government contract awarded to a company with a direct connection to Donald Trump.
A government contract awarded to a company with a direct connection to Donald Trump.
This is of course the contract that allows the Secret Service to rent space in Trump Tower for protecting Trump and his associates.
What can you find?#
All of the data and queries used here are public, so feel free to reproduce the data in your own instance of Neo4j. Neo4j is open source and free to use, you can get it here. To make working with this data even easier, we've created a Neo4j Sandbox Trumpworld example. In addition there are some embedded Neo4j Browser Guides for working with the dataset (introducing Cypher, interesting queries, applying social network analysis techniques to the dataset, etc. )
You can spin up your own Trumpworld Graph Neo4j instance by signing into the Sandbox here.
 The Neo4j Sandbox instance includes Neo4j Browser Guides for working with the data in Neo4j
The Neo4j Sandbox instance includes Neo4j Browser Guides for working with the data in Neo4j
Here are some ideas to get your started:
Suggested areas for research#
What can we learn about cabinet appointees and their connections?
MATCH p=(a)-[r]-(b)
WHERE r.connection CONTAINS "Nominee"
RETURN p
Extending the dataset. What other data sources could we include in the graph to enhance our understanding?
- Campaign contributions from the FEC
- Nonprofit and foundation disclosure data
- Combine with related data from littlesis.org, "the involuntary registry of the 1%"
- Add people involved with the election campaign
- Add more detailed information on the organizations and their setup (location, leadership, deals), e.g. by querying APIs like OpenCorporates or by integrating with the data from Aleph the OCCRP data portal
Can we use centrality algorithms to find "influencers" in the network?
For example, we can examine the connections of the people with the highest PageRank score in the network:
// Find the first degree connections of the people with the highest PageRank score
MATCH (c:Person)
WITH collect(c) AS people
CALL apoc.algo.pageRank(people) YIELD node, score
WITH node, score ORDER BY score LIMIT 5
MATCH p=(node)-[]-()
RETURN p
What are areas you're interested in exploring?
By filtering on names and connection types we can explore the networks around key people and organizations. For example:
// Find the second degree network of Goldman Sachs
MATCH (o:Organization) WHERE o.name CONTAINS "GOLDMAN SACHS"
MATCH p=(o)-[*2]-()
RETURN p
Further work#
Hopefully this post demonstrates what I think are the two most important benefits of using a graph database when doing data journalism type analysis:
- The intuitiveness of the data model and query language. Thinking of your data in terms of graphs allows you to focus on connections in the data, which is often the interesting part when it comes to finding stories in data.
- The ability to extend the data model by combining datasets. The flexibility of the property graph model allows for easily combining datasets and querying across them, as we did here with Trumpworld + USASpending.
There is still much work to be done with this data. Here are some ideas for further improvement:
- The vendor - organization matching was done using an exact string match. There are certainly companies that were not found due to spelling inconsistencies ("EXXONMOBIL" vs "EXXON MOBIL CORP" vs "EXXON MOBIL CORPORATION"). To improve the matching rate, we could resolve the Dun & Bradstreet DUNS number for each organization in Trumpworld (since USASpending data includes DUNS number). Or explore using fuzzy string matching to find high probability matches.
- Adding loan and grant information. In addition to grants, USASpending includes information on loan and grant recipients from the federal government.
- Other datasets. What other dataset would be interesting to add? Campaign finance, foundation / non-profit data?
Subscribe To Will's Newsletter
Want to know when the next blog post or video is published? Subscribe now!