Analyzing A Local Startup Ecosystem With Mattermark, GraphQL, Apollo Client, and Neo4j
William Lyon / April 27, 2017
12 min read •
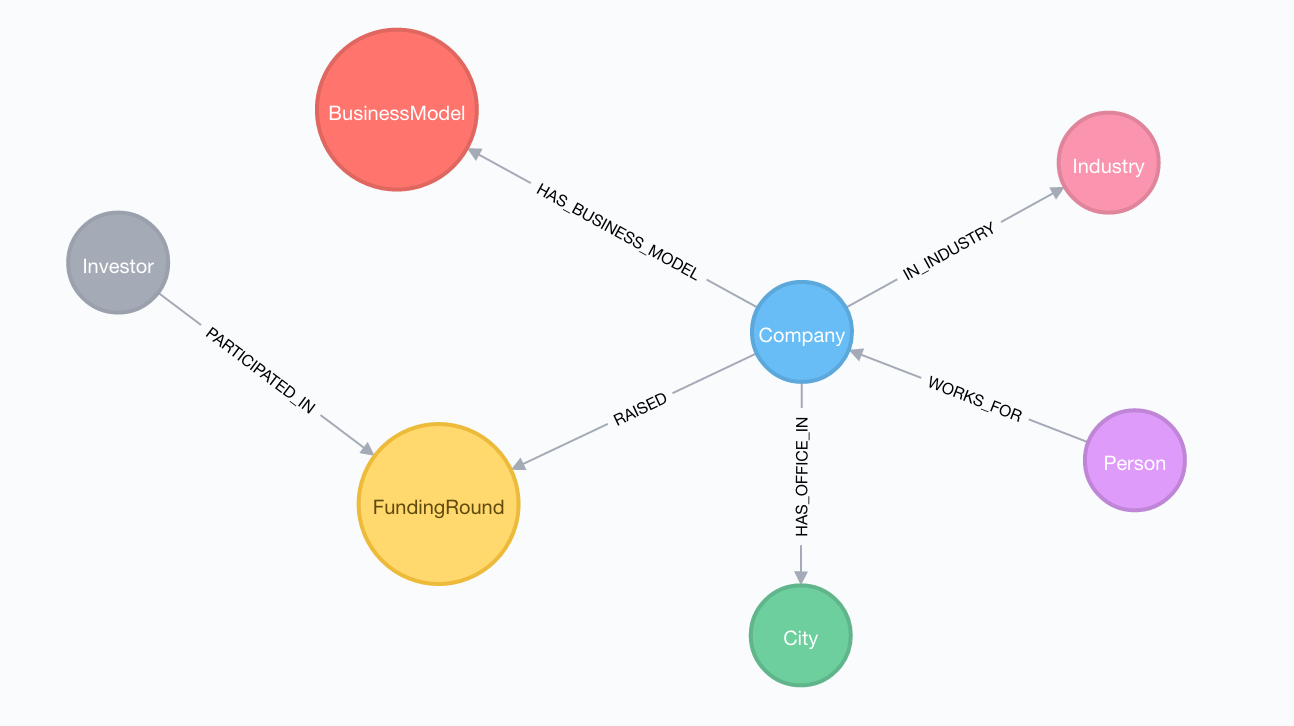 Datamodel for the startup ecosystem graph we'll build with data from Mattermark.
Datamodel for the startup ecosystem graph we'll build with data from Mattermark.
Many web services are converting their publicly facing APIs from REST to GraphQL. Companies like GitHub and Shopify have been leading this transition to GraphQL. In this post we take a look at how we can query the new Mattermark GraphQL API using Apollo Client, storing the results in Neo4j to then see to see what we can learn about a local startup ecosystem.
When I heard about Mattermark's new GraphQL API I had an excuse to go diving into the data around this. Being from Montana, and having worked for several Montana startups (I'm currently in exile in the Bay Area - more on that later) I'm very curious about what is going on in the Montana startup ecosystem. Specifically I wanted to know:
What are the companies in Montana that are raising venture capital? Who are the founders? Who is funding them and what industries are they in?
I've been aware of Mattermark for a while but never really dug into their platform or APIs, but when I heard that they were releasing a beta GraphQL API I knew I had to dig in further. I knew that once I had the data in Neo4j I could do some interesting graph analysis with Cypher. A graph database plus GraphQL!? Sounds like a great way to spend a few hours playing around.
Technologies we'll be using#
- Mattermark API - an API for information about startups, funding, business models, and much more
- GraphQL - a query language for APIs
- Apollo Client - a client for GraphQL
- Neo4j - a graph database
- node.js - we'll write a simple script to fetch data from Mattermark and store in Neo4j
- neo4j-driver - JavaScript driver for Neo4j
Install Dependencies
First, let's take care of all the dependencies we'll need.
Mattermark API#
Mattermark collects information about companies - things like company overviews, funding information, key employees, growth signals, etc. They then apply machine learning techniques to do things like develop indicators about which companies are growing faster than others (for example) and provide this information to help investors make better investment decisions (and for anyone else who wants to use the data). They have an API, and recently announced a beta GraphQL API. To follow along you'll need an API key, which you can get by creating an account at mattermark.com.
GraphQL#
Despite what the name may imply, GraphQL is not a query language for graph databases. Instead it is a query language for APIs. GraphQL is an alternative to REST that allows developers to describe all data and the queries available in the API in a single schema. Client can then query for subsets of this data, defining exactly the data they would like returned in their GraphQL query. As graphql.org says:
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. GraphQL provides a complete and understandable description of the data in your API, gives clients the power to ask for exactly what they need and nothing more, makes it easier to evolve APIs over time, and enables powerful developer tools.
So what does it have to do with graphs? GraphQL makes the observation that all application data is a graph (think of orders that contain products - that's a graph!). Regardless of how it is actually stored (in a relational database, document database, etc) intuitively, application data is a graph since application data is all about objects and how they are connected. GraphQL then allows developers to express their data as a graph and query for the data they want out of this graph from the client.
Let's take a look at a simple example using the Mattermark GraphQL API:
query {
organization(domain:"neo4j.com") {
name
estFounded
}
}
A simple GraphQL query
{
"data": {
"organization": {
"name": "Neo4j",
"estFounded": "2007-01-01"
}
}
}
The data returned matches the structure we've specified in our query. Nothing more, nothing less.
In our script we'll use the graphql-tag library to parse our GraphQL query strings.
npm install --save graphql-tag
Install graphql-tag dependency for parsing GraphQL query strings.
Apollo Client#
Apollo Client is a client for GraphQL. It does lots of smart things like query caching, handling subscriptions, and query prefetching to optimize performance. It integrates with React, Angular, Next.js and others. We can also use Apollo Client in a vanilla javscript script, which is how we'll use it today.
npm install --save apollo-client
Apollo-client is typically used in modern web browsers and makes use of fetch, which does not exist nativiely in node. But we can use a polyfill module that adds a global fetch for our simple node script:
npm install --save isomorphic-fetch
Install isomorphic-fetch polyfill for apollo-client
Then import fetch to expose it as a global:
require(isomorphic-fetch);
We can instantiate an ApolloClient instance by passing in a NetworkInterface object to the ApolloClient constructor. The NetworkInterface object contains the uri of the GraphQL API we'll be using. We'll also need to set the Authorization header in all our GraphQL requests to include our Mattermark API token.
// create apollo client instance
const networkInterface = ApolloClient.createNetworkInterface({
uri: 'https://eapi.mattermark.com/graphql',
opts: {
headers:
{
"Authorization": "Bearer ${MATTERMARK_TOKEN}"
}
}
});
const client = new ApolloClient.constructor(networkInterface);
Create an ApolloClient object.
Neo4j#
Neo4j is a graph database. If you're not familiar with Neo4j, check out some of the other posts on this site or head over to the Neo4j developer page.
As we've seen previously with what Crunchbase has done with the "Business Graph" we can gain insights by modeling this type of data as a graph.
We'll need to download and install Neo4j to store the data we fetch from the Mattermark GraphQL API, or we can spin up a blank Neo4j Sandbox instance here in a few seconds, which is what I'm going to do.
 Spin up a blank Neo4j Sandbox instance, note username, password, ip address, and bolt port. Don't worry, I changed my passsword ;-)
Spin up a blank Neo4j Sandbox instance, note username, password, ip address, and bolt port. Don't worry, I changed my passsword ;-)
We'll use the Neo4j JavaScript driver to connect to Neo4j from our script. We'll use the credentials above to instantiate a driver instance like this:
// npm install --save neo4j-driver
var neo4j = require('neo4j-driver').v1;
var driver = neo4j.driver('bolt://52.87.234.212:33404', neo4j.auth.basic('neo4j', 'messes-leaf-january'));
The Mattermark GraphQL API
We'll be using the new beta Mattermark GraphQL API to query for information about startups, their employees,and funding rounds. Like all GraphQL APIs, the Mattermark API exposes a single endpoint /graphql to which we post our GraphQL queries. Documentation for the API (including the GraphQL schema and example queries) is available here
The Mattermark Semantic Filtering Language (MSFL)#
One thing I found intersting about the Mattermark GraphQL API is that it exposes a filtering language for specifying a query of the Mattermark dataset. A MSFL query is a JSON object that expresses the predicates for the query. For example this MSFL query (taken from the docs):
{
"dataset": "companies",
"filter": {
"and": [
{
"organizationMetrics.employeeCounts.current": {
"gte": 10
}
},
{
"companyPersona.stage": "a"
}
]
}
}
is a query to find all series A companies with 10 or more employees. The API then exposes MSFL through a GraphQL query organizationSummmaryQuery that has a return type of OrganizationSummaryConnection, a type defined in the GraphQL schema specific to a MSFL response. I thought this was an interesting way of exposing a domain specific query language through GraphQL, which I hadn't seen previously.
Querying the Mattermark GraphQL API With Apollo Client
The first query we want to run is "What are all the companies in Montana that have raised venture capital". We can write this query in MSFL:
let msfl = {
"dataset": "companies",
"filter": {
"and": [
{
"offices.location.state.iso2": "MT"
},
{
"companyPersona.lastFundingAmount.value": {
"gte": 0
}
}
]
}
};
Then the msfl object becomes a variable that we can pass into a GraphQL query to retrieve company information for companies that meet this predicate:
let getCompaniesByStateQuery = gql`
query getMontanaCompanies($msfl: String) {
organizationSummaryQuery(msfl: $msfl) {
organizations {
edges {
cursor
node {
id
name
companyPersona {
companyStage
lastFundingAmount {
value
currency
}
lastFundingDate
}
}
}
pageInfo {
hasNextPage
hasPreviousPage
}
queryId
totalResults
currentPage
pageSize
}
}
}
`;
Once we retrieve a result from this query we want to write the company name and id to Neo4j, which we do with this Cypher query:
const INSERT_COMPANY_QUERY = `
MERGE (c:Company {id: $company_id})
ON CREATE SET c.name = $company_name
`;
We're now ready to use apollo-client to query the Mattermark GraphQL API and write the results to Neo4j:
// first, find all companies in MT that have a most recent funding round > 0
client.query({
query: getCompaniesByStateQuery,
variables: {
msfl: JSON.stringify(msfl)
}
})
.then(function(result) {
console.dir(result);
let session = driver.session();
let companies = result.data.organizationSummaryQuery.organizations.edges;
// collect ids of companies matching the criteria
let ids = [];
companies.forEach(function(e){
console.log(e);
session.run(INSERT_COMPANY_QUERY, {company_id: e.node.id, company_name: e.node.name})
.then(function(result) {
console.log(result);
//session.close();
})
.catch(function(error) {
console.log(error);
//session.close();
});
ids.push({id: e.node.id, company_name: e.node.name});
});
})
.catch(function(error){
console.dir(error);
});
Note that we collect the id of each company into an array, ids. This is because the previous organizationSummaryQuery GraphQL query only gives us summary information for each company. But we also want to know about funding rounds, business models, and industries. So we'll need to issue another GraphQL query for more detailed company information:
let getCompanyDetailsQuery = gql`
query getCompanyDetails($id: String) {
organization(id: $id) {
id
name
businessModels {
name
}
industries {
name
}
estFounded
fundingRounds {
series
amountRaised{
value
transactionDate
currency
}
fundingDate
investments {
amount{
value
transactionDate
currency
}
investor{
id
name
description
personnel {
name
title
}
}
}
amountRaised{
value
transactionDate
currency
}
}
domains {
domain
alexaRanks {
weekAgo
}
estimatedMonthlyUniques {
weekAgo
}
}
personnel {
name
title
}
offices {
location {
name
city {
name
}
state {
iso2
}
country {
iso3
}
region {
name
}
}
}
}
}
`;
Then for each detailed company information result from the GraphQL query, we'll write that information to Neo4j with this Cypher query, passing in the organziation root object as a parameter:
const INSERT_COMPANY_DETAILS_QUERY = `
WITH $organization AS org
MATCH (c:Company {id: org.id})
SET c.estFounded = org.estFounded
WITH *
FOREACH (office IN org.offices |
MERGE (city:City {name: office.location.city.name})
MERGE (c)-[:HAS_OFFICE_IN]->(city)
)
FOREACH (bm IN org.businessModels |
MERGE (b:BusinessModel {name: bm.name})
MERGE (c)-[:HAS_BUSINESS_MODEL]->(b)
)
FOREACH (person IN org.personnel |
MERGE (p:Person {name: person.name})
MERGE (p)-[r:WORKS_FOR]->(c)
SET r.title = person.title
)
FOREACH (ind IN org.industries |
MERGE (i:Industry {name: ind.name})
MERGE (c)-[:IN_INDUSTRY]->(i)
)
FOREACH (round IN org.fundingRounds |
CREATE (r:FundingRound {series: round.series})
SET r.amountRaised = toInteger(round.amountRaised.value)
MERGE (c)-[:RAISED]->(r)
FOREACH (investment IN round.investments |
MERGE (investor:Investor {id: investment.investor.id})
SET investor.name = investment.investor.name,
investor.description = investment.investor.description
MERGE (investor)-[:PARTICIPATED_IN]->(r)
)
)
`;
We define a fetchCompanyDetails function to issue the GraphQL query using apollo-client and write the results to Neo4j using the above Cypher query. With that we can use async.mapSeries to iterate over the array of ids that we collected:
async.mapSeries(ids, fetchCompanyDetails, function(error, results) {
console.log(error);
console.log(results);
console.log("ALL DONE!!");
})
Querying Neo4j
The graph model.
Now that we have our data in Neo4j we can use Cypher and the Neo4j Browser to analyze the data we've imported.
We can examine the full graph:
That's great but let's use Cypher to answer some specific questions:
Queries#
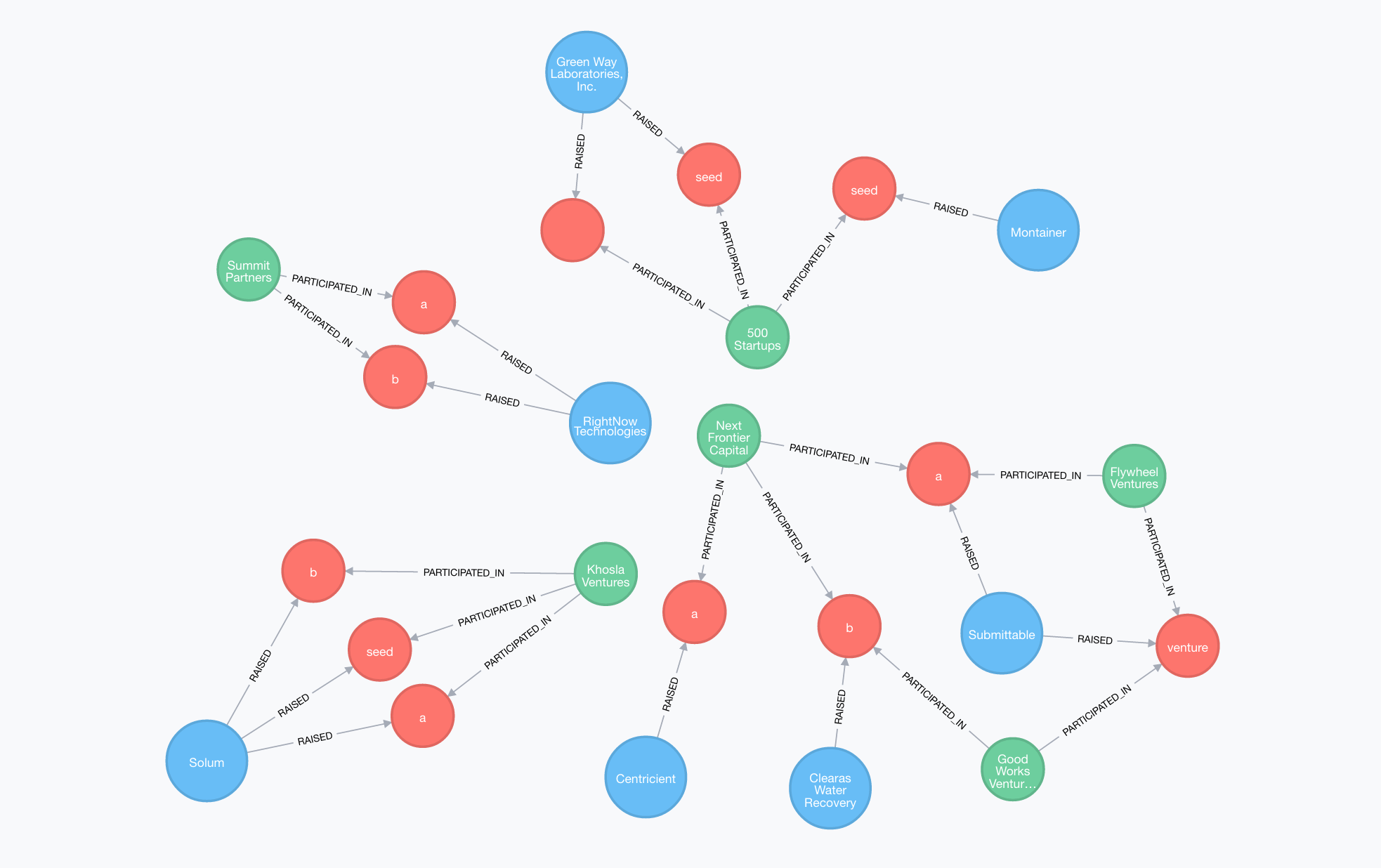
What investors have participated in more than one Funding Round?
// What investors have participated in more than one FundingRound?
MATCH (i:Investor)-[:PARTICIPATED_IN]->(r:FundingRound)<-[:RAISED]-(c:Company)
WHERE size((i)--()) > 1
RETURN *
What companies have raised the most money?
// What companies have raised the most money?
MATCH (c:Company)-[:RAISED]->(r:FundingRound)
RETURN c.name, sum(r.amountRaised) as amount
ORDER BY amount DESC
╒══════════════════════════╤══════════╕
│"c.name" │"amount" │
╞══════════════════════════╪══════════╡
│"LigoCyte Pharmaceuticals"│"36990335"│
├──────────────────────────┼──────────┤
│"ViZn Energy" │"33964591"│
├──────────────────────────┼──────────┤
│"RightNow Technologies" │"31200000"│
├──────────────────────────┼──────────┤
│"Microbion" │"27178689"│
├──────────────────────────┼──────────┤
│"Osprey Medical" │"26830000"│
├──────────────────────────┼──────────┤
│"Solum" │"23500000"│
├──────────────────────────┼──────────┤
│"ViZn Energy Systems" │"16800000"│
├──────────────────────────┼──────────┤
│"KE2 Therm Solutions" │"12006153"│
├──────────────────────────┼──────────┤
│"Schedulicity" │"7700000" │
├──────────────────────────┼──────────┤
│"Centricient" │"6500000" │
├──────────────────────────┼──────────┤
│"Swan Valley Medical" │"5684658" │
├──────────────────────────┼──────────┤
│"ZAF Energy Systems" │"4059434" │
├──────────────────────────┼──────────┤
│"Clearas Water Recovery" │"4000000" │
├──────────────────────────┼──────────┤
│"Blackfoot" │"2500000" │
├──────────────────────────┼──────────┤
│"Rivertop Renewables" │"2160000" │
├──────────────────────────┼──────────┤
│"Submittable" │"2090000" │
├──────────────────────────┼──────────┤
│"Goomzee" │"1685000" │
├──────────────────────────┼──────────┤
│"TEXbase" │"1509025" │
├──────────────────────────┼──────────┤
│"Blue Marble Energy" │"1300000" │
├──────────────────────────┼──────────┤
│"AlgEvolve" │"1147396" │
└──────────────────────────┴──────────┘
We can use the spoon-neo4j Neo4j Browser extension to add charts. Just install spoon-neo4j and run the same query again:
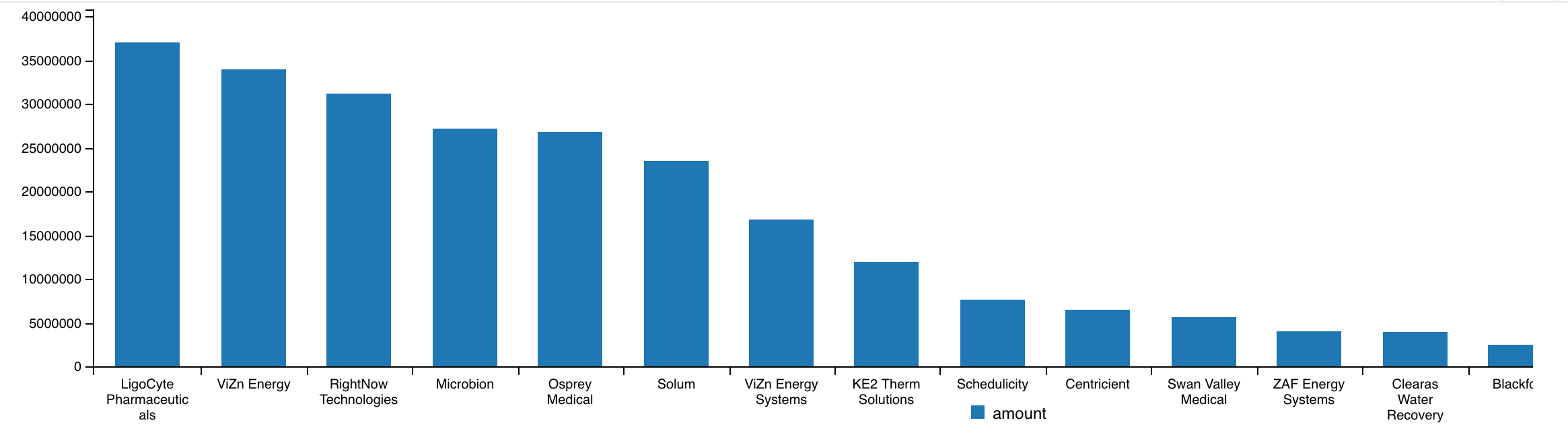
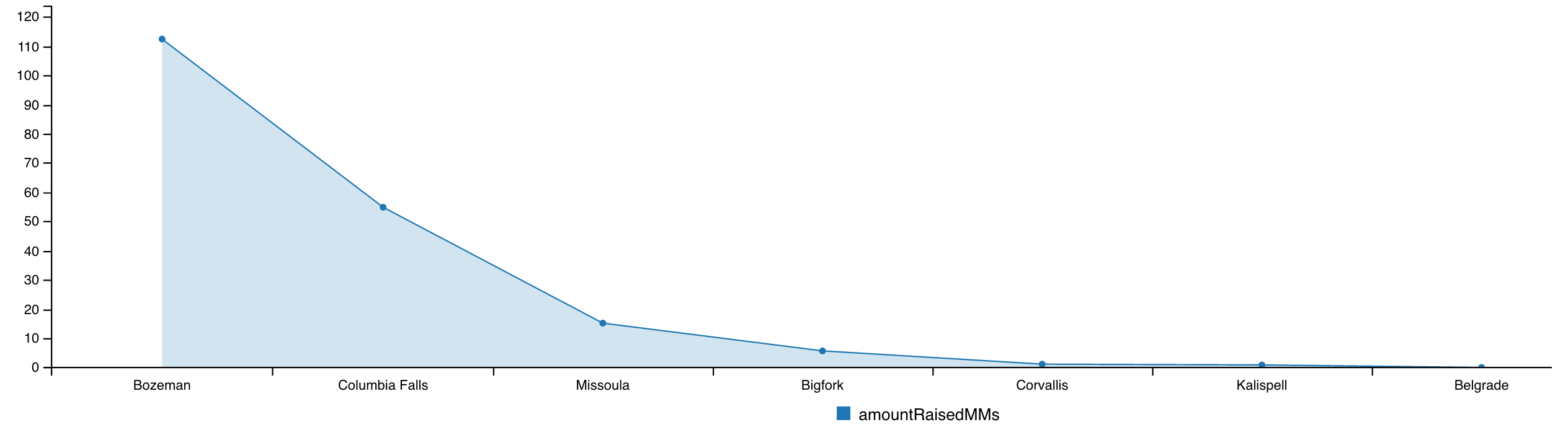
What cities in Montana have the most startup funding?
MATCH (c:Company)-[:HAS_OFFICE_IN]-(city:City)
MATCH (c)-[:RAISED]->(r:FundingRound)
WITH city, sum(r.amountRaised) AS amountRaised ORDER BY amountRaised DESC
RETURN city.name, apoc.number.format(amountRaised) AS amt
╒════════════════╤═════════════╕
│"city.name" │"amt" │
╞════════════════╪═════════════╡
│"Bozeman" │"112,343,049"│
├────────────────┼─────────────┤
│"Columbia Falls"│"54,824,025" │
├────────────────┼─────────────┤
│"Missoula" │"15,176,000" │
├────────────────┼─────────────┤
│"Bigfork" │"5,684,658" │
├────────────────┼─────────────┤
│"Corvallis" │"1,147,396" │
├────────────────┼─────────────┤
│"Kalispell" │"872,420" │
├────────────────┼─────────────┤
│"Belgrade" │"25,000" │
└────────────────┴─────────────┘
Again, we can use spoon-neo4j to visualize this with a chart:
MATCH (c:Company)-[:HAS_OFFICE_IN]-(city:City)
MATCH (c)-[:RAISED]->(r:FundingRound)
RETURN city.name, 1.0 * sum(r.amountRaised) / 1000000 AS amountRaisedMMs ORDER BY amountRaisedMMs DESC LIMIT 10
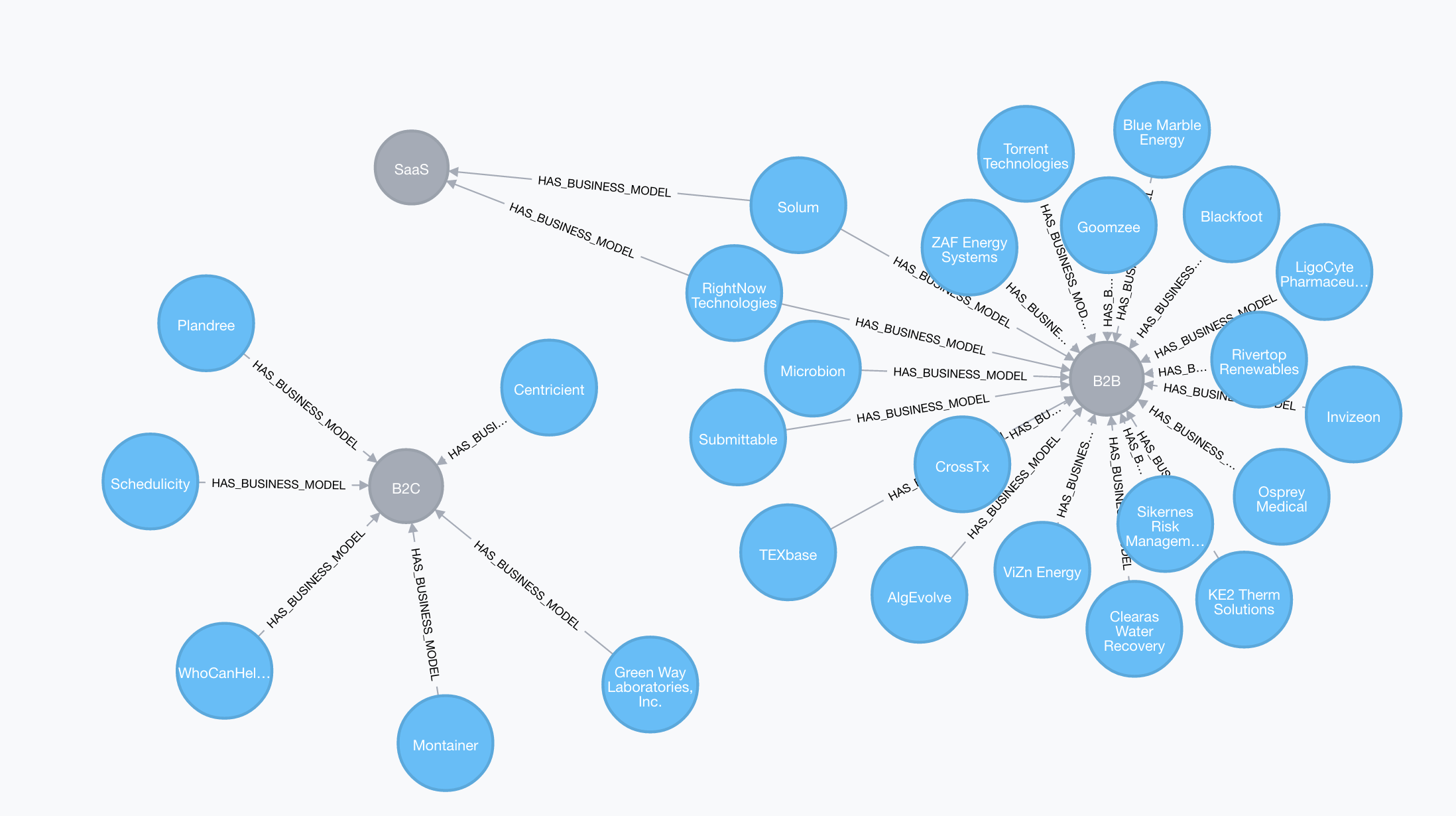
Business Models
MATCH (c:Company)-[in:HAS_BUSINESS_MODEL]->(b:BusinessModel)
RETURN *
Cities by industries
It is also interesting to explore what the most common industries
First we update the graph:
MATCH (c:Company)-[:HAS_OFFICE_IN]->(city:City)
MATCH (c:Company)-[in:IN_INDUSTRY]->(i:Industry)
MERGE (city)-[:HAS_COMPANY_IN]->(i)
Then we can query:
MATCH (city:City)-[in:HAS_COMPANY_IN]->(i:Industry)
RETURN *
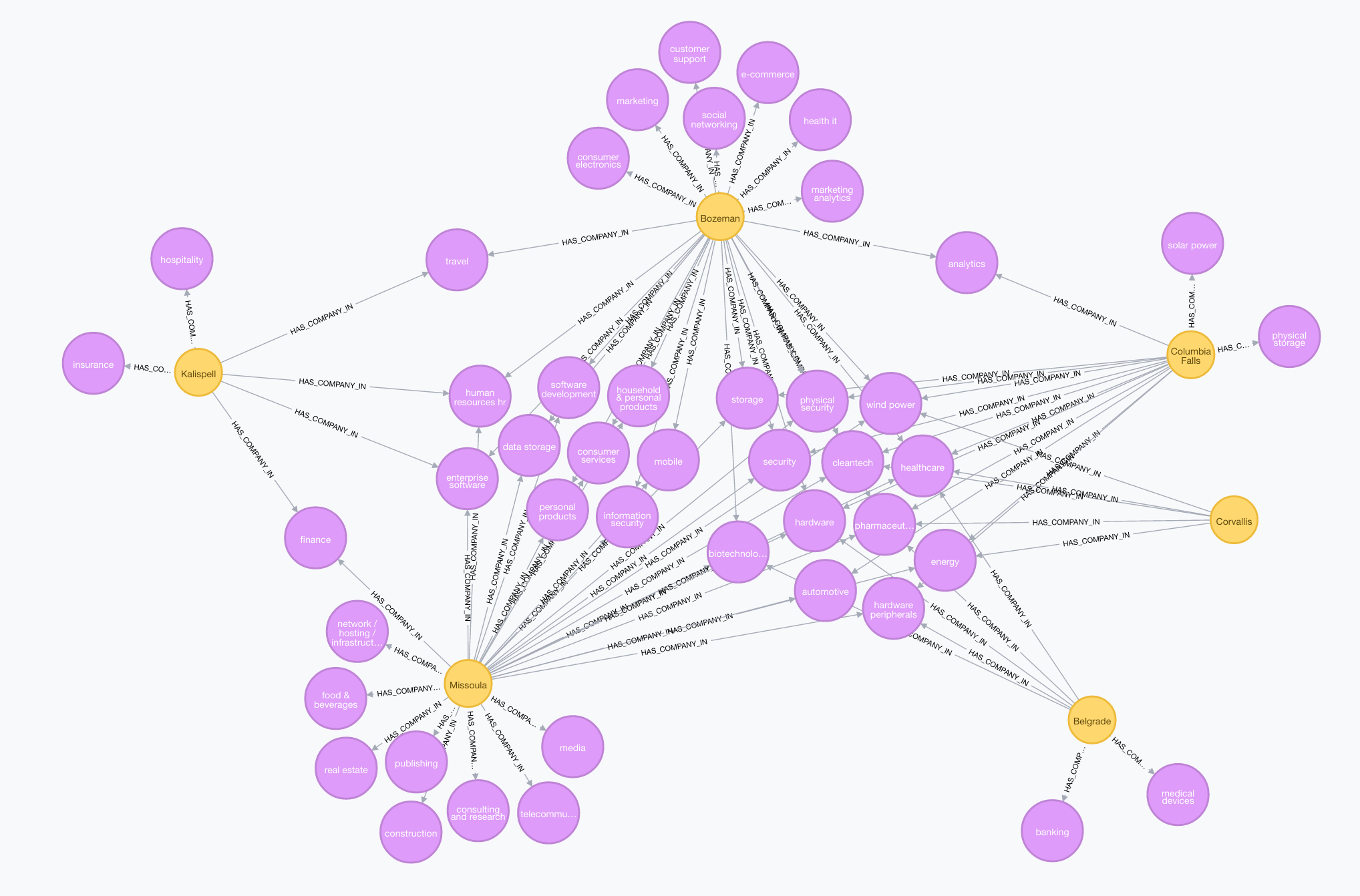
This is interesting as it shows us what industries are common across cities. With the force directed layout of the graph visualization in Neo4j Browser we can see clusters of Industry nodes that are shared across combinations of cities, and what Industry nodes are found only in single cities. For example, we can see that Bozeman has social networking and marketing analytics startups, while Missoula has media and publishing startups - industries that are not common for statups in other Montana cities.
All code is on GitHub here.
Subscribe To Will's Newsletter
Want to know when the next blog post or video is published? Subscribe now!