Introducing legis-graph - US Congressional Data With Govtrack and Neo4j
William Lyon
September 20, 2015
9 min read
Interactions among members of any large organization are naturally a graph, yet the tools we use to collect and analyze data about these organizations often ignore the graphiness of the data and instead map the data into structures (such as relational databases) that make taking advantage of the relationships in the data much more difficult when it comes time to analyze the data. Collaboration networks are a perfect example. So let's focus on one of the most powerful collaboration networks in the world: the US Congress.
Govtrack.us#
Creating government transparency and civic engagement through novel uses of technology. - govtrack.us
Govtrack.us is a government transparency website that helps the general public find and track bills in the US Congress and keep track of things like a congressperon's voting record and committee activity.
From Govtrack.us:
We bring together the status of U.S. federal legislation, voting records, congressional district maps, and more ... and make it easier to understand.
Govtrack provides many web based tools for exploring and analyzing the US Congress, including a feature I find particularly interesting called Sponsorship Analysis. You can see an example of this here. Govtrack also provides an API and makes bulk data avilable. Bulk data is provided in a mix of JSON, XML, and YAML.
Introducing legis-graph: US Congress in a graph#
The goal of legis-graph is to provide a way of converting the data provided by Govtrack into a rich property-graph model that can be inserted into Neo4j for analysis or integrating with other datasets.
The code and instructions are available in this Github repo. The ETL workflow works like this:
- A shell script is used to rsync data from Govtrack for a specific Congress (i.e. the 114th Congress). The Govtrack data is a mix of JSON, CSV, and YAML files. It includes information about legislators, committees, votes, bills, and much more.
- To extract the pieces of data we are interested in for legis-graph a series of Python scripts are used to extract and transform the data from different formats into a series of flat CSV files.
- The third component is a series of Cypher statements that make use of
LOAD CSVto efficiently import this data into Neo4j.
To get started with legis-graph in Neo4j you can follow the instructions here. Alternatively, a Neo4j data store dump is available here for use without having to execute the import scripts. We are currently working to streamline the ETL process so this may change in the future, but any updates will be appear in the Github README.
This project began during preparation for a graph database focused Meetup presentation. George Lesica and I wanted to provide an interesting dataset in Neo4j for new users to explore.
The Data Model#
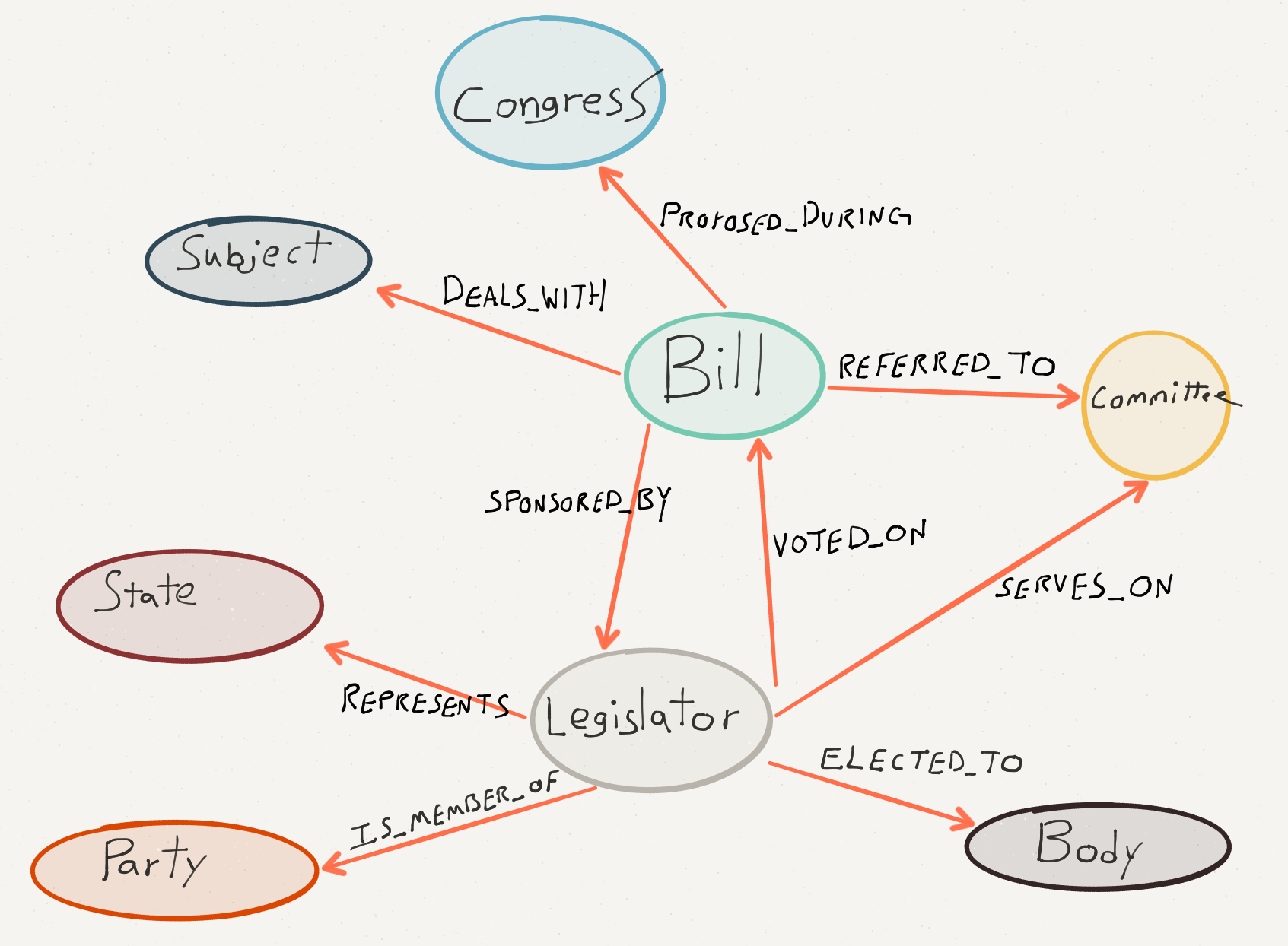
As you can see from the diagram above, the datamodel is rich and captures quite a bit of information about the actions of legislators, committees, and bills in Congress. Information about what properties are currently included is available here.
Querying legis-graph#
I recently moved to California and realized I know pretty much nothing about politics in California (other than the exploits of the Governator, of course), so I thought a good test of legis-graph would be getting started with learning about California's Congresspeople.
Who represents California in Congress?
An easy start, tell me the names of California's elected representatives in Congress.
MATCH (s:State {code: "CA"})<-[:REPRESENTS]-(l:Legislator)
RETURN l.firstName + " " + l.lastName as Legislator;
+-------------------------+
| Legislator |
+-------------------------+
| "Tony Cárdenas" |
| "Raul Ruiz" |
| "Mark Takano" |
| "Alan Lowenthal" |
| "Juan Vargas" |
| "Xavier Becerra" |
| "Karen Bass" |
| "Barbara Boxer" |
| "Dianne Feinstein" |
| "Jerry McNerney" |
| "Tom McClintock" |
| "Kevin McCarthy" |
| "Doris Matsui" |
| "Zoe Lofgren" |
| "Barbara Lee" |
| "Loretta Sanchez" |
| "Adam Schiff" |
| "Lucille Roybal-Allard" |
| "Edward Royce" |
| "Dana Rohrabacher" |
| "Nancy Pelosi" |
| "Grace Napolitano" |
| "Devin Nunes" |
| "Anna Eshoo" |
| "Jim Costa" |
| "Jeff Denham" |
| "Susan Davis" |
| "Judy Chu" |
| "Ken Calvert" |
| "Lois Capps" |
| "Duncan Hunter" |
| "Darrell Issa" |
| "Michael Honda" |
| "Sam Farr" |
| "John Garamendi" |
| "Steve Knight" |
| "Mark DeSaulnier" |
| "Ted Lieu" |
| "Pete Aguilar" |
| "Mimi Walters" |
| "Norma Torres" |
| "Brad Sherman" |
| "Jackie Speier" |
| "Linda Sánchez" |
| "Mike Thompson" |
| "Maxine Waters" |
| "Janice Hahn" |
| "David Valadao" |
| "Julia Brownley" |
| "Paul Cook" |
| "Eric Swalwell" |
| "Jared Huffman" |
| "Ami Bera" |
| "Doug LaMalfa" |
| "Scott Peters" |
+-------------------------+
55 rows
83 ms
OK, so California has lots of members of Congress. How many are from which parties?
Breakdown by party
MATCH (s:State {code: "CA"})<-[:REPRESENTS]-(l:Legislator)
MATCH (l)-[r:IS_MEMBER_OF]->(p:Party)
WITH p.name as party, count(r) as num
RETURN party, num;
+--------------------+
| party | num |
+--------------------+
| "Republican" | 14 |
| "Democrat" | 41 |
+--------------------+
2 rows
56 ms
So California is definitely a blue state...
We can also examine this data using the Neo4j Browser.
Let's visualize California's elected representatives in both bodies of Congress:
MATCH (s:State {code: "CA"})<-[:REPRESENTS]-(l:Legislator) WHERE has(l.wikipediaID)
MATCH (l)-[:ELECTED_TO]->(b:Body)
RETURN s,l,b
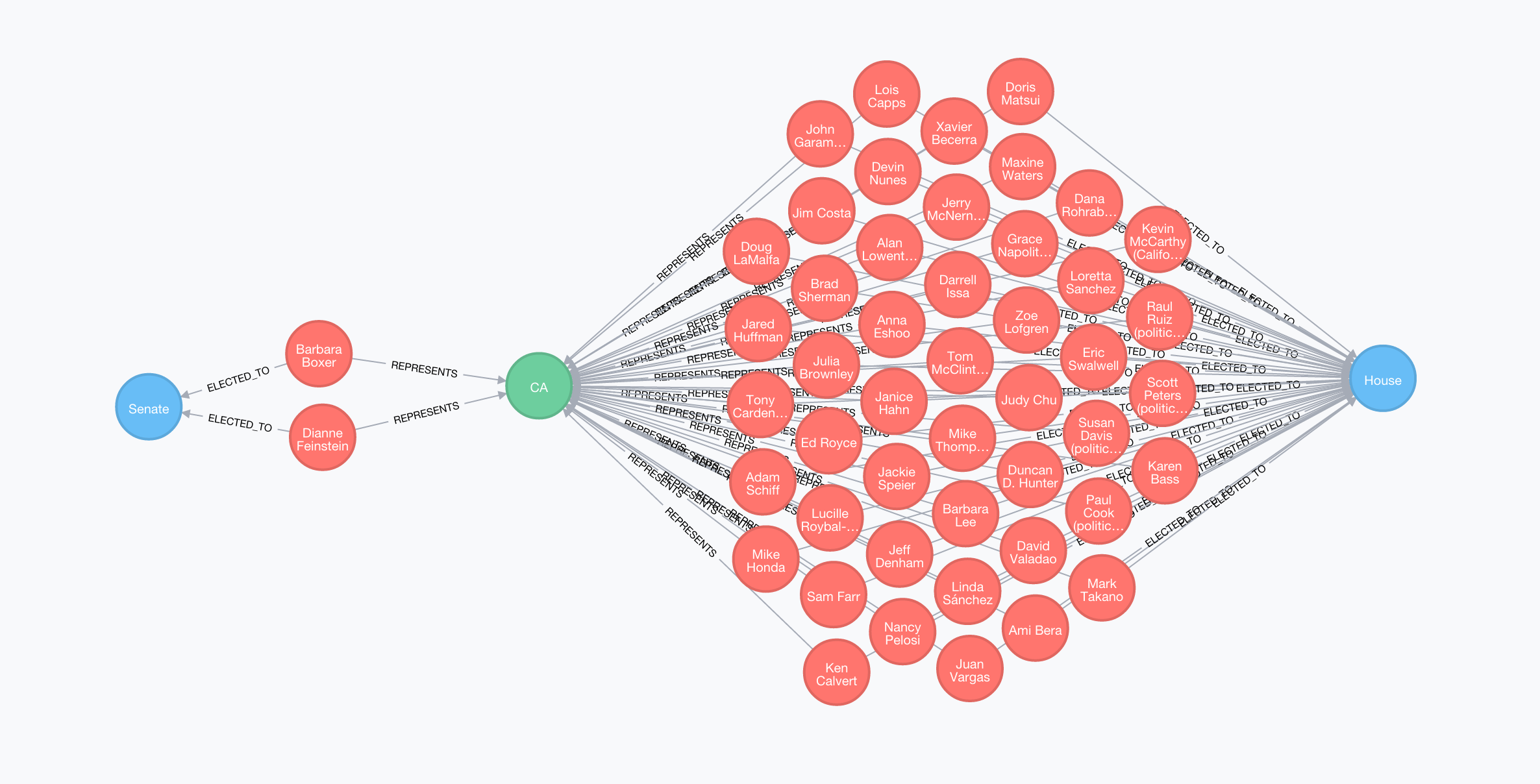
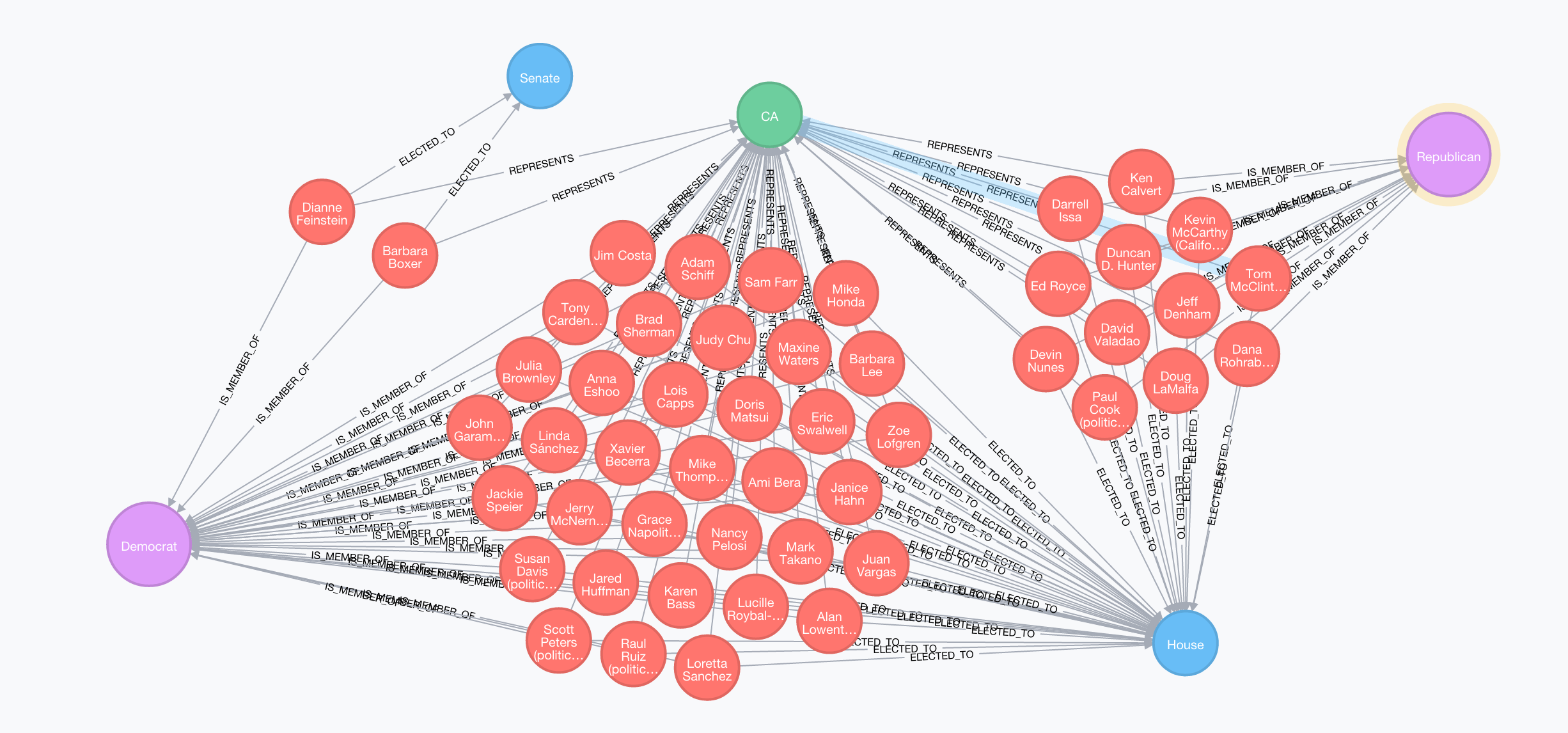
We can include Party in the visual as well:
MATCH (s:State {code: "CA"})<-[:REPRESENTS]-(l:Legislator)
MATCH (l)-[:ELECTED_TO]->(b:Body)
MATCH (l)-[:IS_MEMBER_OF]->(p:Party)
RETURN s,l,b,p
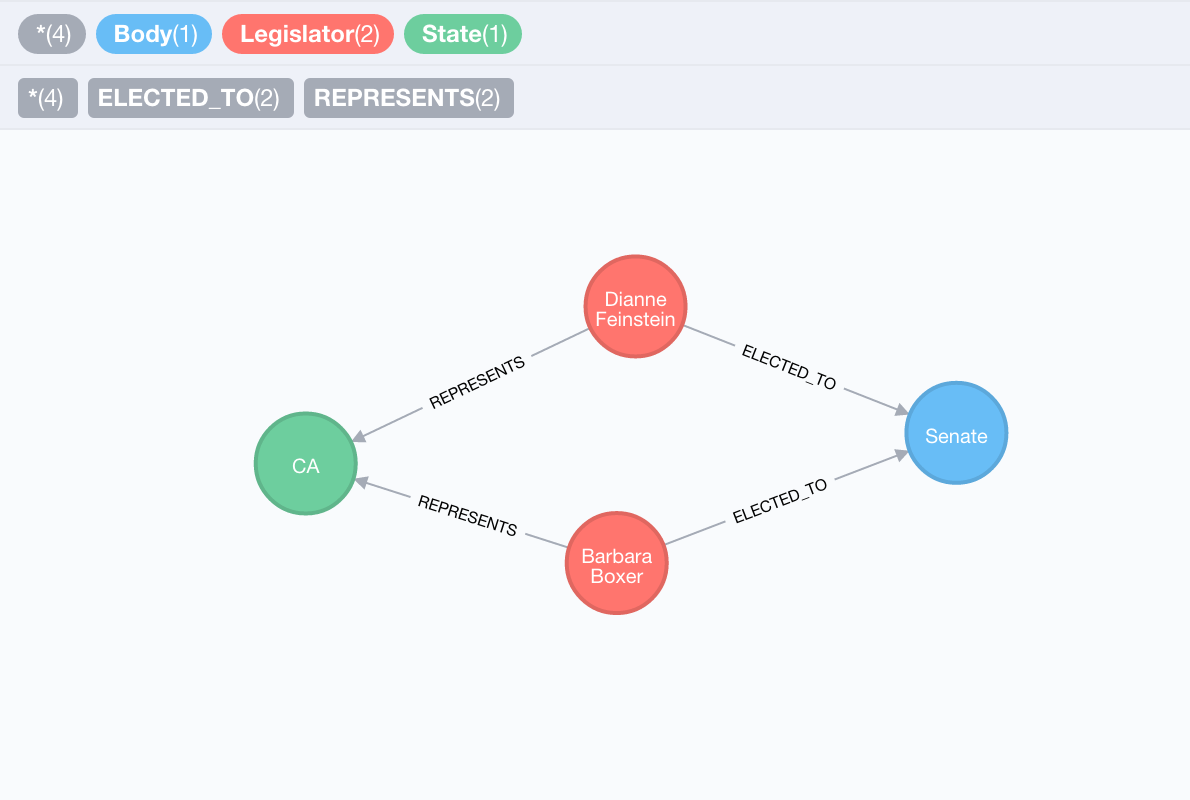
Who are the Senators?
Let's limit our analysis to only Senators representing California:
MATCH (s:State {code: "CA"})<-[:REPRESENTS]-(l:Legislator)
MATCH (l)-[:ELECTED_TO]->(b:Body {type: "Senate"})
MATCH (l)-[:IS_MEMBER_OF]->(p:Party)
RETURN s,l,b,p
What Committees do the California senators serve on?
Each legislator serves on one or more congressional committees. In addition to other administrative powers, each committee has jurisdiction over bills of a given subject matter. By serving on certain committees legislators can gain more influence over bills that fall in their committees' jurisdictions. For example, legislators who serve on the House Committee on Agriculture have a greater influence over agricultural policies and federal funding available for agricultural programs because of the power of their committee. Examining committee membership is an initial method to examine the areas where a legislator has more influence over policy.
From our datamodel we see that we have a SERVES_ON relationship to determine which Committees our Senators are serving.
MATCH (ca:State {code: "CA"})<-[:REPRESENTS]-(l:Legislator)
MATCH (l)-[:ELECTED_TO]->(senate:Body {type: "Senate"})
MATCH (l)-[:SERVES_ON]->(c:Committee)
RETURN l,c
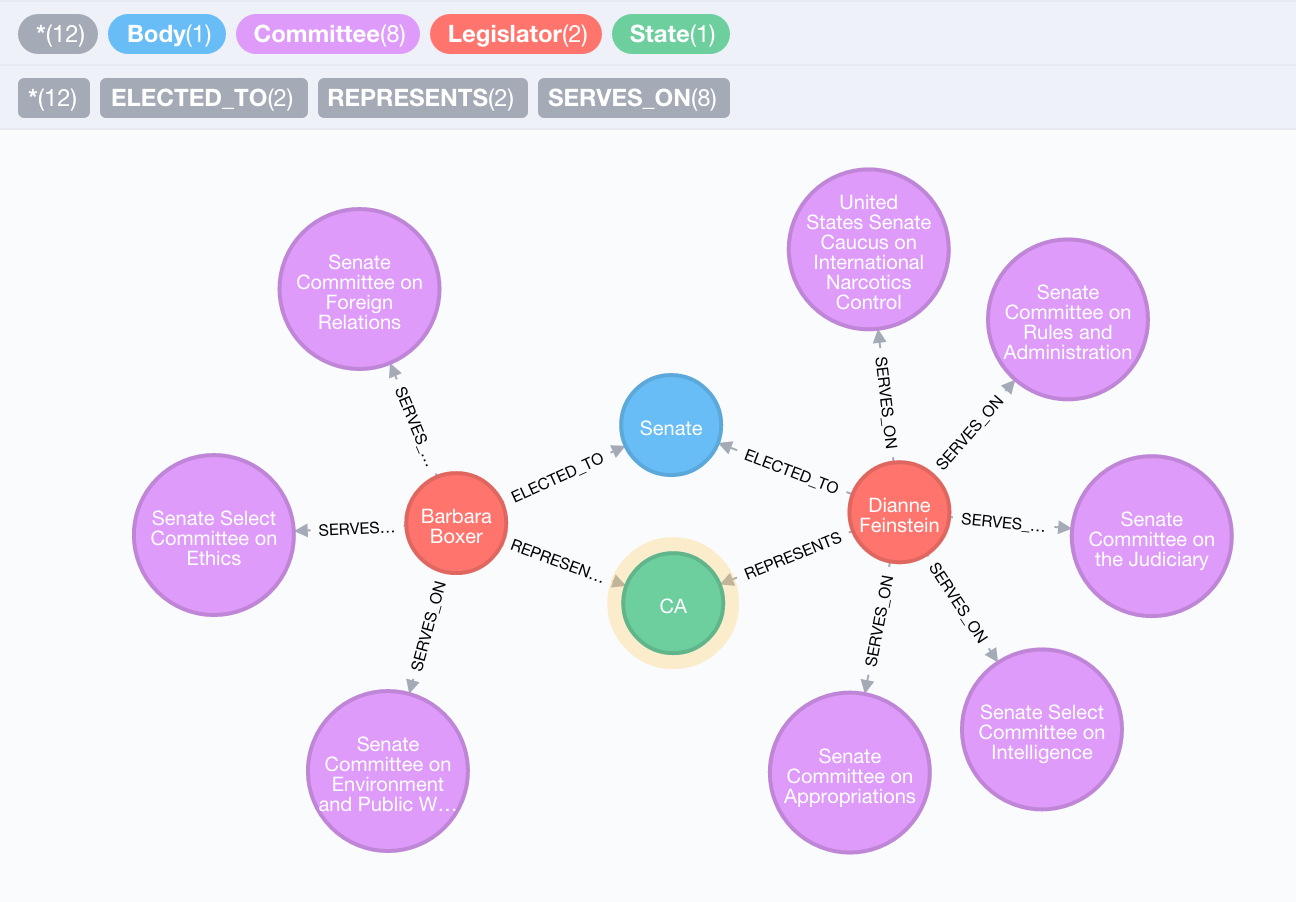
What kinds of bills are overseen by these committees?
First, let's examine the Bills that were referred to a single committee on which Diane Feinstein serves, the Senate Committee on Appropriations. We can do this by matching on the thomasID property on the Committee node.
MATCH (ca:State {code: "CA"})<-[:REPRESENTS]-(l:Legislator)
MATCH (l)-[:ELECTED_TO]->(senate:Body {type: "Senate"})
MATCH (l)-[:SERVES_ON]->(c:Committee {thomasID: "SSAP"})
MATCH (c)<-[:REFERRED_TO]-(b:Bill)
RETURN ca, senate, l, c, b
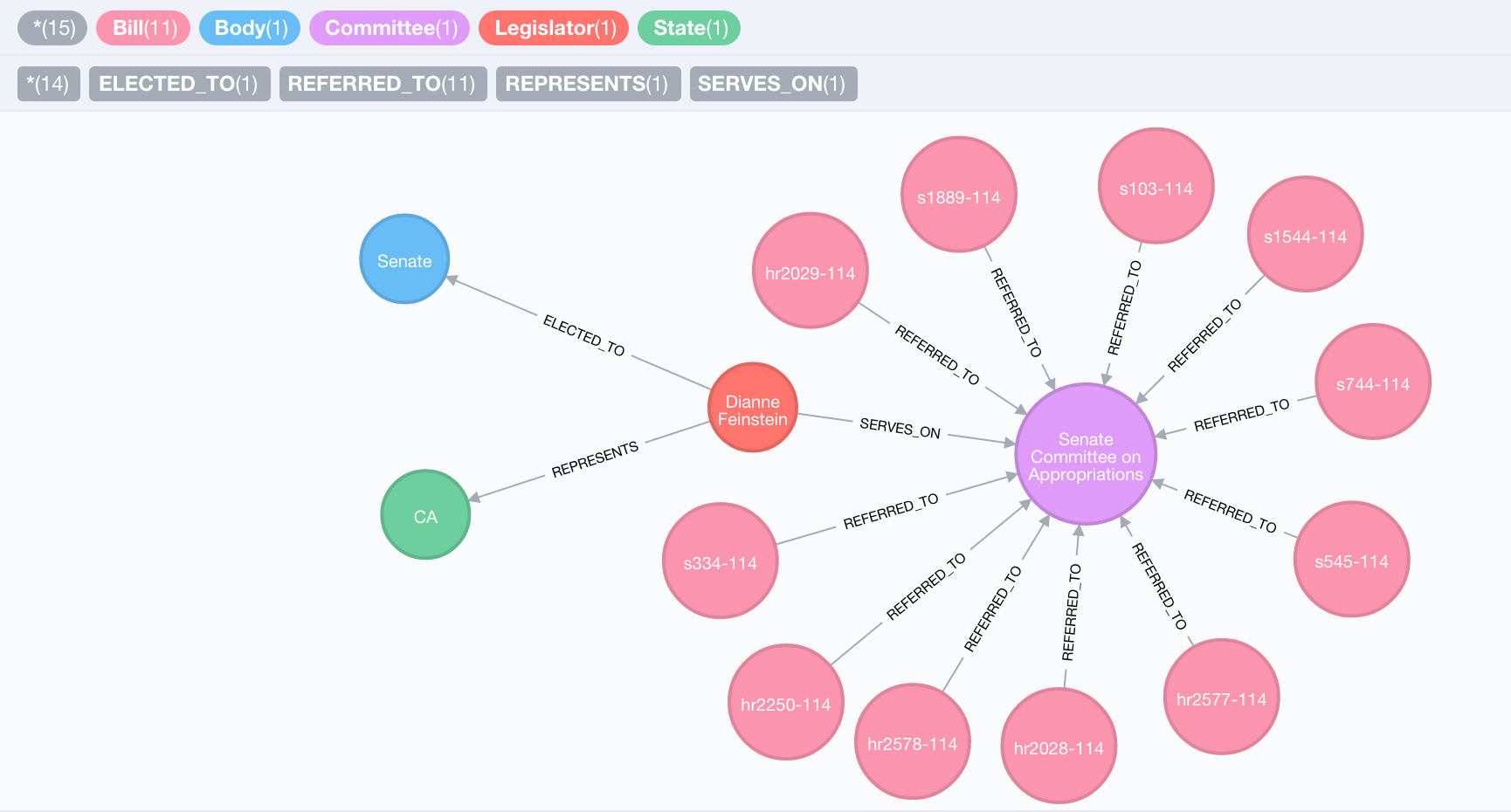
So we can see 11 Bills that have been referred to the Senate Committee on Appropriations. We have information about each Bill in the properties of the node, including the title and description of the Bill, whether it was vetoed or enacated. We could also follow VOTED_ON relationships to see how individual Legislators voted on each Bill.
However, I'm interested in learning more about the subjects these Bills are dealing with. What I want to know is the answer to this question: "For Legislators representing California, what subjects might they have influence over based on the Committees on which they serve".
Here is just a subset of those subjects for California's Senators:
MATCH (ca:State {code: "CA"})<-[:REPRESENTS]-(l:Legislator)
MATCH (l)-[:ELECTED_TO]->(senate:Body {type: "Senate"})
MATCH (l)-[:SERVES_ON]->(c:Committee)
MATCH (c)<-[:REFERRED_TO]-(b:Bill)
MATCH (b)-[:DEALS_WITH]->(s:Subject)
RETURN ca, senate, l, c, b, s
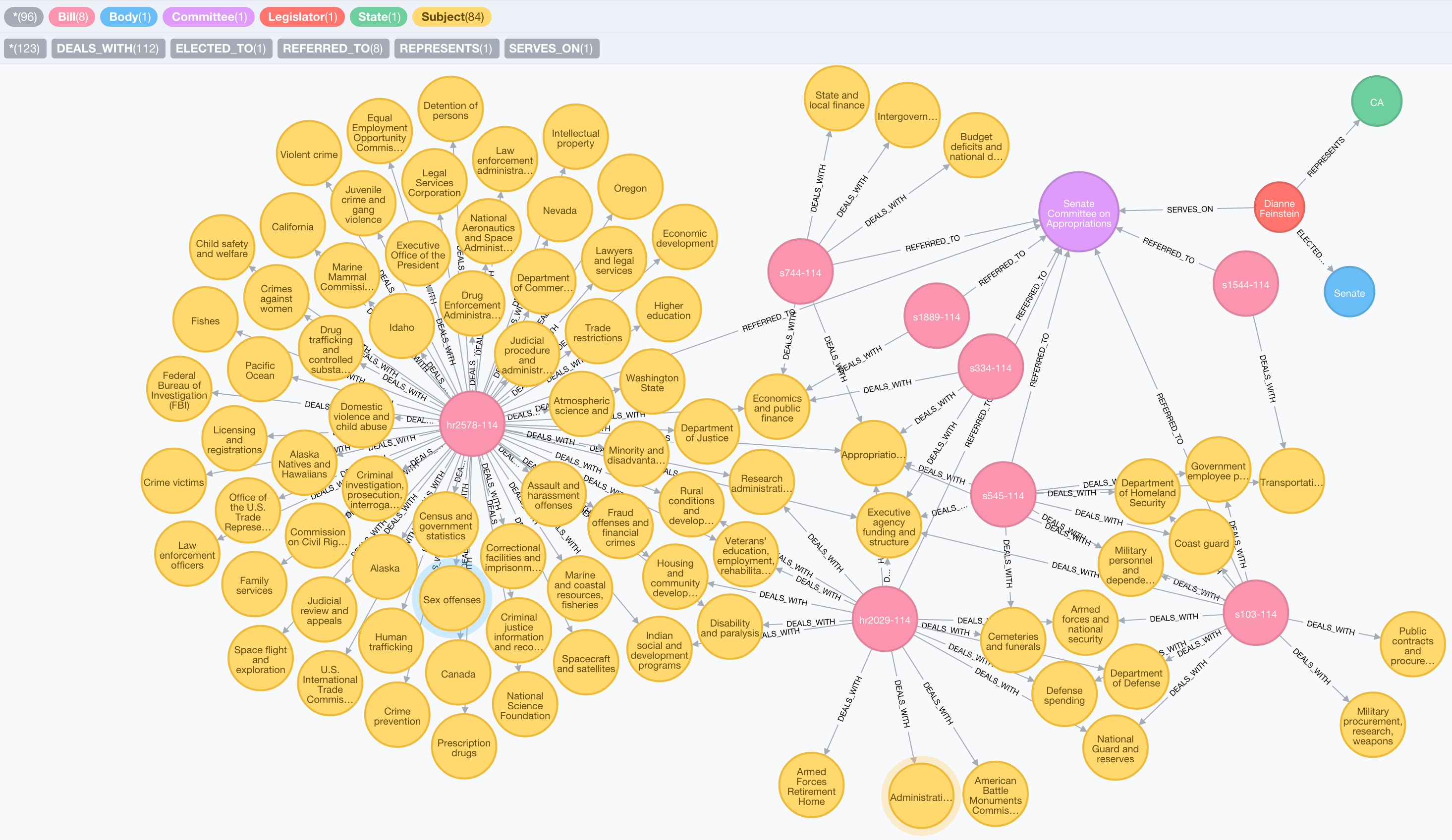
We can draw more insight from the data if we count the number of bills referred to these Committees for each subject.
MATCH (s:State {code: "CA"})<-[:REPRESENTS]-(l:Legislator)
MATCH (l)-[:ELECTED_TO]->(b:Body) WHERE b.type="Senate"
MATCH (l)-[:SERVES_ON]-(c:Committee)<-[:REFERRED_TO]-(bill:Bill)
MATCH (bill)-[r:DEALS_WITH]->(subject:Subject)
WITH count(r) as num, subject
RETURN subject.title AS subject, num ORDER BY num DESC LIMIT 25;
+------------------------------------------------------------+
| subject | num |
+------------------------------------------------------------+
| "Crime and law enforcement" | 100 |
| "Congressional oversight" | 75 |
| "Environmental protection" | 66 |
| "Government information and archives" | 54 |
| "Administrative law and regulatory procedures" | 53 |
| "International affairs" | 49 |
| "Government operations and politics" | 40 |
| "Civil actions and liability" | 35 |
| "State and local government operations" | 34 |
| "Government studies and investigations" | 32 |
| "Law enforcement administration and funding" | 32 |
| "Criminal procedure and sentencing" | 31 |
| "Criminal investigation, prosecution, interrogation" | 31 |
| "Executive agency funding and structure" | 29 |
| "Environmental Protection Agency (EPA)" | 29 |
| "Immigration" | 29 |
| "Environmental regulatory procedures" | 27 |
| "Water quality" | 26 |
| "Criminal justice information and records" | 25 |
| "Transportation and public works" | 24 |
| "Intergovernmental relations" | 23 |
| "Wildlife conservation and habitat protection" | 23 |
| "Administrative remedies" | 22 |
| "Crime victims" | 21 |
| "Licensing and registrations" | 21 |
+------------------------------------------------------------+
25 rows
293 ms
This has been a brief overview of some of the data available in legis-graph. Much more complex analysis is possible and I hope those interested will find this project useful. If you find any errors or want to request changes to the data model, please submit an issue on the project's Github page.
Stay Updated
Get notified about new posts and videos