Natural Language Processing With Neo4j - Mining Paradigmatic Word Associations
William Lyon
June 16, 2015
13 min read
Mining word associations from a body of text is often one of the first Natural Language Processing techniques used when mining text data. Word associations are useful for performing NLP tasks such as part of speech tagging, parsing, entity extraction, etc. We will take a brief look at one type of word association called paradigmatic association and show how we can use the Neo4j graph database to help model our text corpus as a graph and implement a simple paradigmatic relation mining algorithm.
Mining word associations#
There are two common types of word associations in natural language processing, paradigmatic and systagmatic:
- Paradigmatic: words A and B are paradigmatically related if they can be substituted for each other. This indicates they belong in the same class, such as "Monday" and "Thursday" or "Cat" and "Dog.
- Syntagmatic: words that can be combined with each other, such as "cold" and "weather".
For this post we will only concern ourselves with paradigmatic associations.
Computing paradigmatic similarity#
The basic steps to compute paradigmatic relations:
- Represent each word by its context
- Compute context similarity
- Words with high context similarity likely have paradigmatic relation
1) Represent each word by its context#
Consider a simple text document that consists of sentences like this:
My cat eats fish on Saturday.
His dog eats turkey on Tuesday.
...
What words occur within similar context in each sentence? How could we answer this question? We need some way to represent the context for a given word. We do this by defining functions to compute pieces of the context of a given word:
Right1("cat") = {"eats", "ate", "is", "has", ...}
Left1("cat") = {"my", "his", "big", "a", "the", ...}
This allows us to represent word context as a series of sets of words.
2) Compute context similarity#
To compute a measure of paradigmatic relation we take an aggregation of the similarity of relative contexts. For example:
Sim("Cat", "Dog") =
Sim(Left1("Cat"), Left1("Dog")) +
Sim(Right1("Cat"), Right1("Dog"))
We can use the Jaccard index as a measure of similarity.
3) Words with high context similarity likely have paradigmatic relation#
Once we have computed this measure of similarity we can simply look for word pairs that have a high measure of similarity.
NOTE: this is a relatively simplistic approach. This method could be imporoved by expanding the size of the context window (for example, including Left2, Window2 word context sets), handling stop words, and term frequency based transformations to adjust similarity scores.
Modeling text data as an adjacency graph#
We can model text data as an adjacency graph where each word is a node and an edge between two nodes indicates that the words appear next to each other in the text corpus. The data model we will use looks like this:
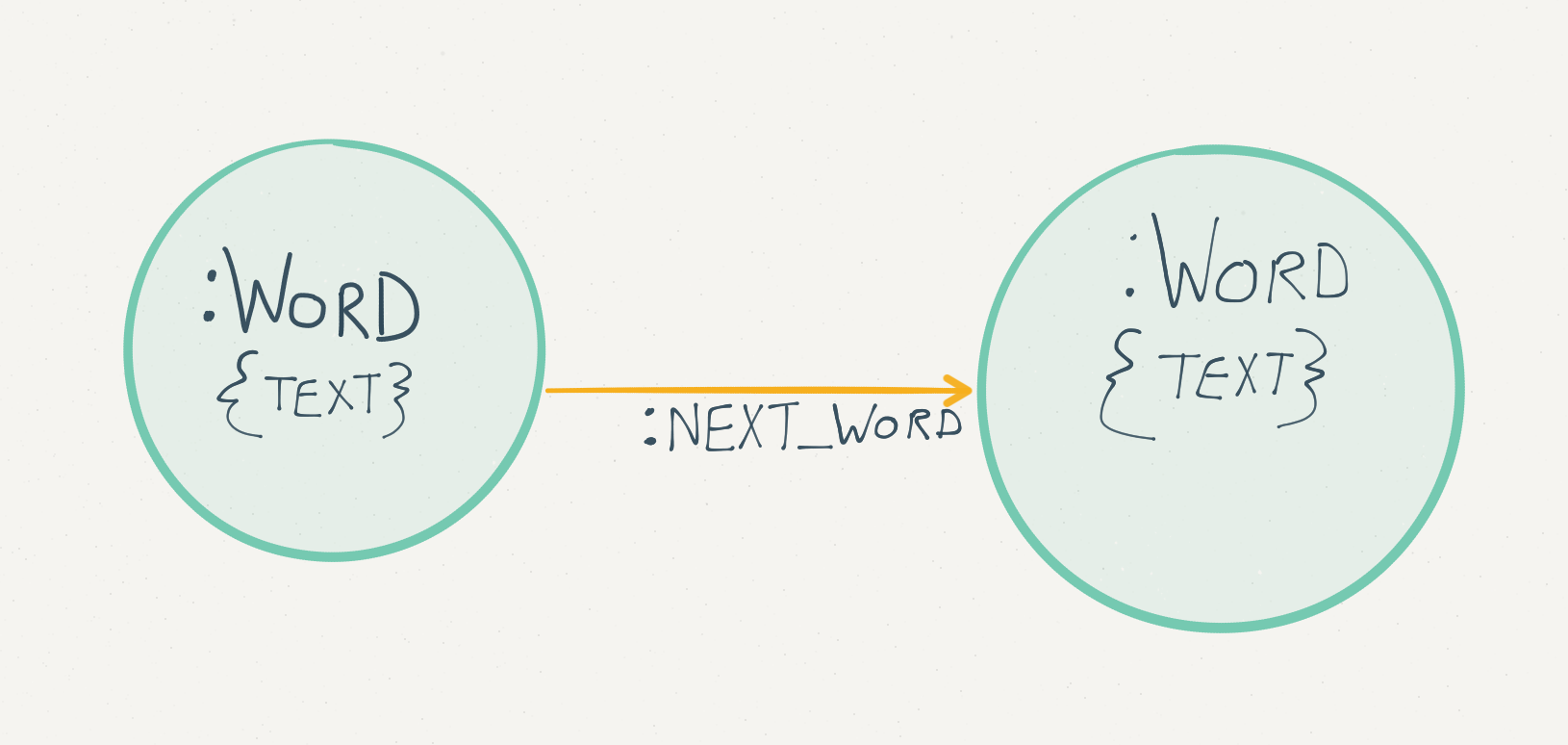
As an example, consider the following sentence:
My cat eats fish on Saturday.
Using our data model this would appear as follows in our adjacency graph:
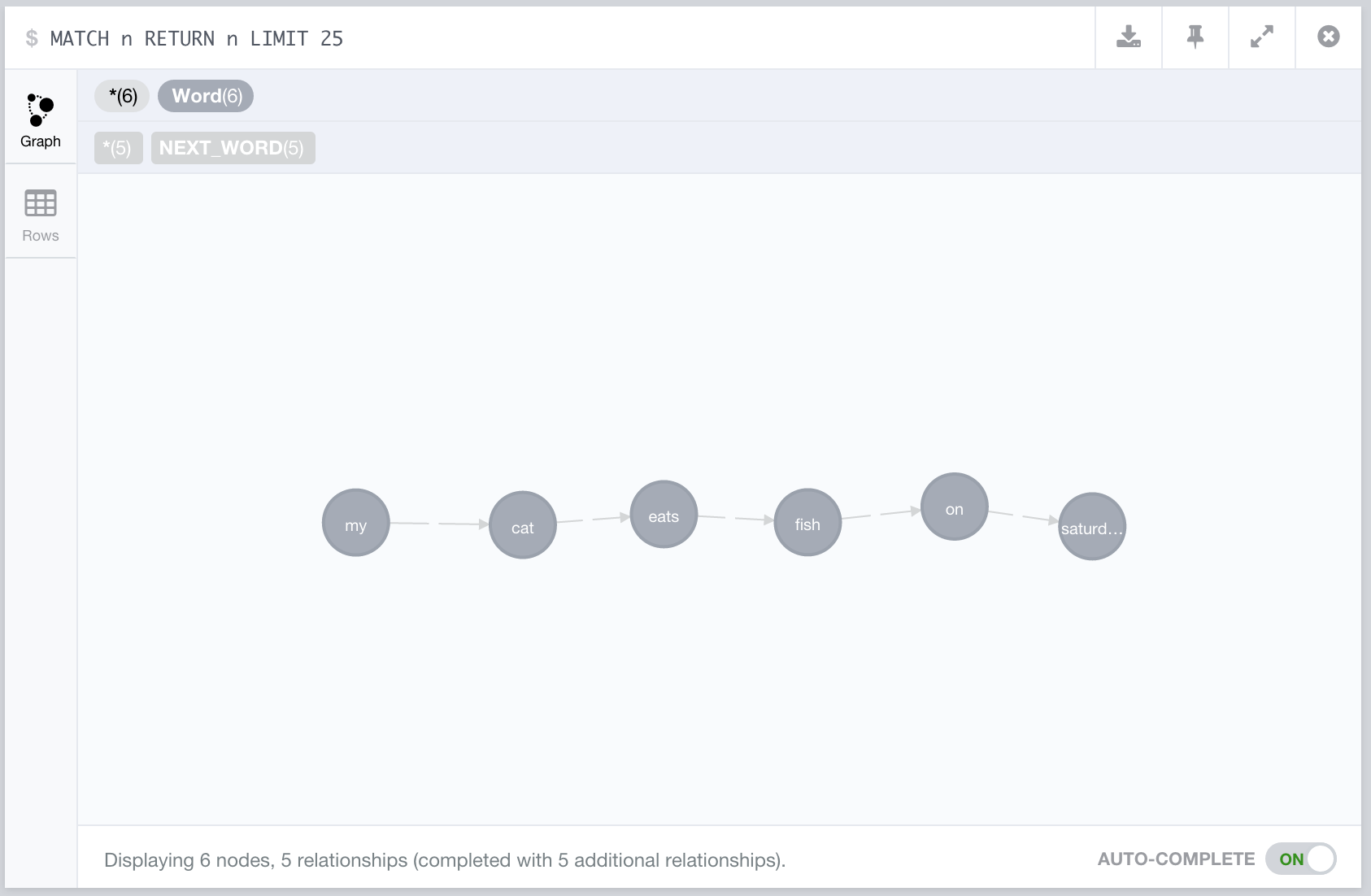
If we add another sentence:
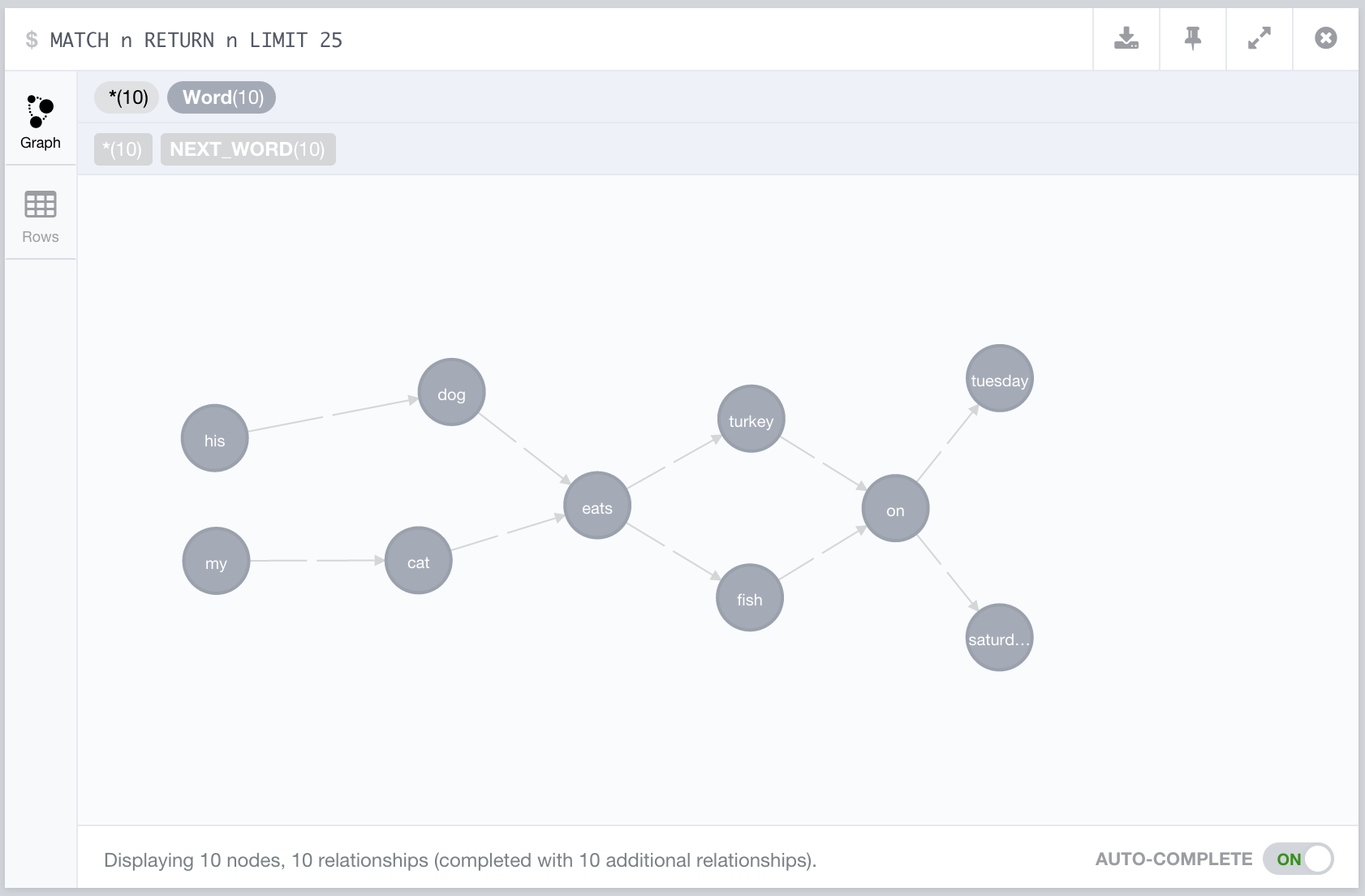
His dog eats turkey on Tuesday.
Our graph is updated like this:
We will use the Neo4j graph database to implement this data model. The text corpus used here is the CEEAUS corpus which is distributed with the MeTA NLP library.
We will first see how we can load this text corpus into Neo4j using a Python script. Then we will explore how we can query the data to mine paradigmatic relations using Cypher, the Neo4j query language.
Loading the data#
The data is stored in a single file, with each sentence on a single line. We define a Python function to load this file, normalize the text a bit and execute a Cypher query for each line of text to insert into the graph as per the data model we have defined above. Here's the Python code for data insertion:
from py2neo import Graph
import re, string
# default uri for local Neo4j instance
graphdb = Graph('http://neo4j:neo4j@localhost:7474/db/data')
# parameterized Cypher query for data insertion
# t is a query parameter. a list with two elements: [word1, word2]
INSERT_QUERY = '''
FOREACH (t IN {wordPairs} |
MERGE (w0:Word {word: t[0]})
MERGE (w1:Word {word: t[1]})
CREATE (w0)-[:NEXT_WORD]->(w1)
)
'''
# convert a sentence string into a list of lists of adjacent word pairs
# also convert to lowercase and remove punctuation using a regular expression
# arrifySentence("Hi there, Bob!) = [["hi", "there"], ["there", "bob"]]
def arrifySentence(sentence):
sentence = sentence.lower()
sentence = sentence.strip()
exclude = set(string.punctuation)
regex = re.compile('[%s]' % re.escape(string.punctuation))
sentence = regex.sub('', sentence)
wordArray = sentence.split()
tupleList = []
for i, word in enumerate(wordArray):
if i+1 == len(wordArray):
break
tupleList.append([word, wordArray[i+1]])
return tupleList
# load our text corpus into Neo4j
def loadFile():
tx = graphdb.cypher.begin()
with open('data/ceeaus.dat', encoding='ISO-8859-1') as f:
count = 0
for l in f:
params = {'wordPairs': arrifySentence(l)}
tx.append(INSERT_QUERY, params)
tx.process()
count += 1
# process in batches of 100 insertion queries
if count > 100:
tx.commit()
tx = graphdb.cypher.begin()
count = 0
f.close()
tx.commit()
Mining word relations#
Now that we've inserted our data we need some way to query it to discover word relations.
A Cypher / Python Approach#
We can write a simple Cypher query to find the Right1 and Left1 sets quite easily. We can also define some Python methods to handle these Cypher queries and perform some simple set operations to compute Jaccard similarity for a word pair:
# get the set of words that appear to the left of a specified word in the text corpus
LEFT1_QUERY = '''
MATCH (s:Word {word: {word}})
MATCH (w:Word)-[:NEXT_WORD]->(s)
RETURN w.word as word
'''
# get the set of words that appear to the right of a specified word in the text corpus
RIGHT1_QUERY = '''
MATCH (s:Word {word: {word}})
MATCH (w:Word)<-[:NEXT_WORD]-(s)
RETURN w.word as word
'''
# return a set of all words that appear to the left of `word`
def left1(word):
params = {
'word': word.lower()
}
tx = graphdb.cypher.begin()
tx.append(LEFT1_QUERY, params)
results = tx.commit()
words = []
for result in results:
for line in result:
words.append(line.word)
return set(words)
# return a set of all words that appear to the right of `word`
def right1(word):
params = {
'word': word.lower()
}
tx = graphdb.cypher.begin()
tx.append(RIGHT1_QUERY, params)
results = tx.commit()
words = []
for result in results:
for line in result:
words.append(line.word)
return set(words)
# compute Jaccard coefficient
def jaccard(a,b):
intSize = len(a.intersection(b))
unionSize = len(a.union(b))
return intSize / unionSize
# we define paradigmatic similarity as the average of the Jaccard coefficents of the `left1` and `right1` sets
def paradigSimilarity(w1, w2):
return (jaccard(left1(w1), left1(w2)) + jaccard(right1(w1), right1(w2))) / 2.0
This allows us to compute a measure of Paradigmatic similarity for arbitrary word pairs:
In [174]: paradigSimilarity("school", "university") Out[174]: 0.2153846153846154
A Pure Cypher Approach#
The Cypher / Python approach above doesn't really allow us to identify the most paradigmatically similar words. For example, we really only can ask "what is the paradigmatic similarity between words x,y". What we really want to ask is "what are the word pairs that are most paradigmatically similar?" To do this we will use a pure Cypher approach to compare word pairs and update the graph with a :RELATED_TO relationship. This relationship will store the similarity score. Once this query runs we can query for word relations using this new :RELATED_TO edge.
Here's the query:
MATCH (s:Word)
// Get right1, left1
MATCH (w:Word)-[:NEXT_WORD]->(s)
WITH collect(DISTINCT w.word) as left1, s
MATCH (w:Word)<-[:NEXT_WORD]-(s)
WITH left1, s, collect(DISTINCT w.word) as right1
// Match every other word
MATCH (o:Word) WHERE NOT s = o
WITH left1, right1, s, o
// Get other right, other left1
MATCH (w:Word)-[:NEXT_WORD]->(o)
WITH collect(DISTINCT w.word) as left1_o, s, o, right1, left1
MATCH (w:Word)<-[:NEXT_WORD]-(o)
WITH left1_o, s, o, right1, left1, collect(DISTINCT w.word) as right1_o
// compute right1 union, intersect
WITH FILTER(x IN right1 WHERE x IN right1_o) as r1_intersect,
(right1 + right1_o) AS r1_union, s, o, right1, left1, right1_o, left1_o
// compute left1 union, intersect
WITH FILTER(x IN left1 WHERE x IN left1_o) as l1_intersect,
(left1 + left1_o) AS l1_union, r1_intersect, r1_union, s, o
WITH DISTINCT r1_union as r1_union, l1_union as l1_union, r1_intersect, l1_intersect, s, o
WITH 1.0*length(r1_intersect) / length(r1_union) as r1_jaccard,
1.0*length(l1_intersect) / length(l1_union) as l1_jaccard,
s, o
WITH s, o, r1_jaccard, l1_jaccard, r1_jaccard + l1_jaccard as sim
CREATE UNIQUE (s)-[r:RELATED_TO]->(o) SET r.paradig = sim;
We iterate over word pairs, fetch the right1 and left1 word sets, then perform the equivilent of union and intersection operations that allow us to compute the Jaccard coefficient for each word pair. Finally, we update the graph with this coefficent in a new :RELATED_TO relationship.
Querying for word relations#
Now that we've updated the graph with these word association scores we can write simple Cypher queries to discover word associations.
Paradigmatic relations for "school"#
What are the words most strongly paradigmatically related to the word "school"?
MATCH (s:Word {word: 'school'} )-[r:RELATED_TO]->(o)
RETURN s.word,o.word,r.paradig as sim ORDER BY sim DESC LIMIT 25;
+-----------------------------------------------+
| s.word | o.word | sim |
+-----------------------------------------------+
| "school" | "university" | 0.35416666666666663 |
| "school" | "studies" | 0.35279106858054227 |
| "school" | "working" | 0.3497129735935706 |
| "school" | "parents" | 0.33613445378151263 |
| "school" | "college" | 0.33519813519813524 |
| "school" | "society" | 0.3310029130253849 |
| "school" | "parttime" | 0.3220510229856024 |
| "school" | "study" | 0.3186426358772177 |
| "school" | "money" | 0.31618037135278515 |
| "school" | "eating" | 0.31335453100158983 |
| "school" | "place" | 0.3115313895455739 |
| "school" | "experience" | 0.30545975141537063 |
| "school" | "work" | 0.3031372549019608 |
| "school" | "life" | 0.30304354157565166 |
| "school" | "smoker" | 0.29819694868238555 |
| "school" | "jobs" | 0.2965686274509804 |
| "school" | "living" | 0.29284676833696444 |
| "school" | "future" | 0.2874499332443258 |
| "school" | "hard" | 0.28233938346297893 |
| "school" | "children" | 0.2812025508654722 |
| "school" | "studying" | 0.27817343946376205 |
| "school" | "food" | 0.27809596538118875 |
| "school" | "restaurant" | 0.2743995912110373 |
| "school" | "meal" | 0.2705982542048116 |
| "school" | "friends" | 0.2692307692307693 |
+-----------------------------------------------+
25 rows
45 ms
Strong paradigmatic relation#
What are the strongest paradigmatically related words in the text corpus?
MATCH (s)-[r:RELATED_TO]->(o)
RETURN s.word,o.word,r.paradig AS sim ORDER BY sim DESC LIMIT 100;
+---------------------------------------------------+
| s.word | o.word | sim |
+---------------------------------------------------+
| "opinion" | "idea" | 0.39954526663910706 |
| "a" | "the" | 0.39918436823602943 |
| "students" | "college" | 0.393037294302489 |
| "students" | "people" | 0.3798992202990593 |
| "students" | "smokers" | 0.37755673858223593 |
| "in" | "for" | 0.37120642515379354 |
| "for" | "in" | 0.37120642515379354 |
| "important" | "hard" | 0.37101588316810574 |
| "opinion" | "area" | 0.36708144796380093 |
| "opinion" | "situation" | 0.3667582417582418 |
| "important" | "necessary" | 0.3656898656898657 |
| "important" | "bad" | 0.35802139037433156 |
| "school" | "university" | 0.35416666666666663 |
| "students" | "you" | 0.35373408158860353 |
| "important" | "harmful" | 0.3533992213237496 |
| "school" | "studies" | 0.35279106858054227 |
| "for" | "of" | 0.35274323661808615 |
| "to" | "and" | 0.35257738943248285 |
| "school" | "working" | 0.3497129735935706 |
| "students" | "restaurants" | 0.3489169719469919 |
| "important" | "difficult" | 0.3485156912637829 |
| "students" | "student" | 0.34606662818504164 |
| "for" | "that" | 0.34368031605589777 |
| "students" | "parents" | 0.33853521126760566 |
| "opinion" | "place" | 0.3381635025184037 |
| "for" | "to" | 0.33750185739002114 |
| "to" | "for" | 0.33750185739002114 |
| "students" | "nonsmokers" | 0.33671364061040177 |
| "school" | "parents" | 0.33613445378151263 |
| "school" | "college" | 0.33519813519813524 |
| "opinion" | "fact" | 0.3350840336134454 |
| "opinion" | "reasons" | 0.3310381355932204 |
| "school" | "society" | 0.3310029130253849 |
| "students" | "money" | 0.3286558659692988 |
| "have" | "do" | 0.3284722920647692 |
| "for" | "but" | 0.32701345186452413 |
| "important" | "reason" | 0.3252759802055577 |
| "for" | "by" | 0.3252038356724162 |
| "my" | "our" | 0.3236480567977502 |
| "important" | "good" | 0.3223516563523844 |
| "school" | "parttime" | 0.3220510229856024 |
| "for" | "if" | 0.32164442810636096 |
| "my" | "their" | 0.32032052127726696 |
| "opinion" | "statement" | 0.3194444444444444 |
| "opinion" | "problem" | 0.31904269972451793 |
| "opinion" | "point" | 0.31894736842105265 |
| "school" | "study" | 0.3186426358772177 |
| "students" | "restaurant" | 0.31855802425422675 |
| "students" | "work" | 0.3179591836734694 |
| "school" | "money" | 0.31618037135278515 |
| "opinion" | "lives" | 0.3159090909090909 |
| "opinion" | "day" | 0.3156288156288156 |
| "in" | "and" | 0.3154907057525759 |
| "in" | "of" | 0.3153160870310091 |
| "in" | "at" | 0.31521761006289306 |
| "for" | "and" | 0.3140333542277307 |
| "opinion" | "case" | 0.3134920634920635 |
| "school" | "eating" | 0.31335453100158983 |
| "have" | "get" | 0.312328440147989 |
| "school" | "place" | 0.3115313895455739 |
| "opinion" | "country" | 0.3101851851851852 |
| "to" | "that" | 0.30992732204777806 |
| "important" | "studying" | 0.30947775628626695 |
| "students" | "them" | 0.3093731519810763 |
| "for" | "so" | 0.3077891508736062 |
| "students" | "smoker" | 0.30633078730904817 |
| "students" | "us" | 0.30616821341202966 |
| "important" | "well" | 0.3059533175976921 |
| "school" | "experience" | 0.30545975141537063 |
| "opinion" | "workplace" | 0.3048855905998763 |
| "school" | "work" | 0.3031372549019608 |
| "school" | "life" | 0.30304354157565166 |
| "opinion" | "reason" | 0.30277349768875195 |
| "for" | "from" | 0.3025785639266867 |
| "have" | "make" | 0.3020345644760418 |
| "students" | "working" | 0.3019127064374789 |
| "students" | "smoking" | 0.3011066418324483 |
| "for" | "on" | 0.3011051106321491 |
| "for" | "as" | 0.30039366281771396 |
| "in" | "to" | 0.300318818247031 |
| "to" | "in" | 0.300318818247031 |
| "opinion" | "space" | 0.3003003003003003 |
| "students" | "society" | 0.300220818254309 |
| "opinion" | "condition" | 0.3001605136436597 |
| "for" | "with" | 0.29984269706562056 |
| "in" | "but" | 0.2997641267562301 |
| "school" | "smoker" | 0.29819694868238555 |
| "students" | "time" | 0.29796635538346405 |
| "opinion" | "rule" | 0.2975825672454886 |
| "opinion" | "matter" | 0.2975543478260869 |
| "important" | "precious" | 0.2971576227390181 |
| "in" | "that" | 0.2970460614152203 |
| "important" | "place" | 0.2969177779740351 |
| "important" | "dangerous" | 0.29680644832159986 |
| "important" | "much" | 0.2967315570706618 |
| "school" | "jobs" | 0.2965686274509804 |
| "have" | "be" | 0.296095994591854 |
| "opinion" | "meal" | 0.29527272727272724 |
| "opinion" | "way" | 0.2952157388777107 |
| "to" | "of" | 0.29506851814362445 |
+---------------------------------------------------+
100 rows
425 ms
All Python code is available here.
Final note: Many of the NLP ideas and examples here were borrowed from the Coursera course Text Mining and Analytics by Dr. ChengXiang Zhai.
Stay Updated
Get notified about new posts and videos