Twizzard, A Tweet Recommender System Using Neo4j
William Lyon
March 13, 2014
7 min read

I spent this past weekend hunkered down in the basement of the local Elk's club, working on a project for a hackathon. The project was a tweet ranking web application. The idea was to build a web app that would allow users to login with their Twitter account and view a modified version of their Twitter timeline that shows them tweets ranked by importance. Spending hours every day scrolling through your timeline to keep up with what's happening in your Twitter network? No more, with Twizzard!
System structure#
Here's a diagram of the system:
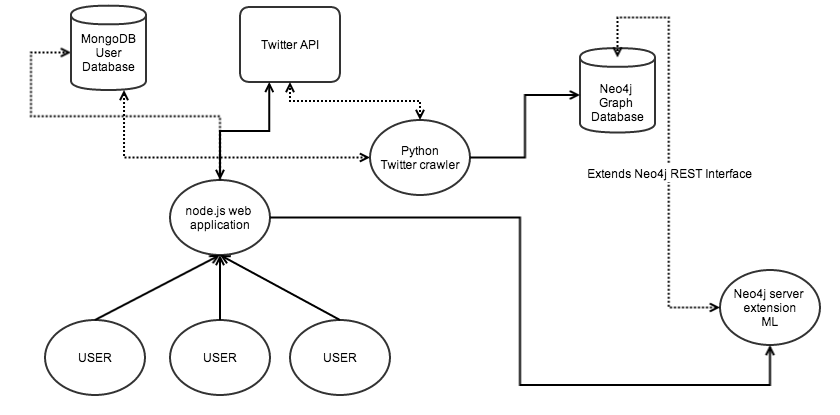
- Node.js web application (using Express framework)
- MongoDB database for storing basic user data
- Integration with Twitter API, allowing for Twitter authentication
- Python script for fetching Twitter data from Twitter API
- Neo4j graph database for storing Twitter network data
- Neo4j unmanaged server extension, providing additional REST endpoint for querying / retrieving ranked timelines per user
Hosted platforms#
Being able to spin up hosted instances of our tech stack simplifies the process of putting this project together.
- GitHub - It goes without saying that we used GitHub for version control, making collaboration with my teammate who handled all the design work quite pleasant.
- Heroku - Heroku's PaaS for web hosting is great. Free tier is perfect for getting small projects going.
- MongoLab - This was my first time using MongoLab's hosted MongoDB service. No complaints, worked great! Also free tier was perfect for getting started.
- GrapheneDB - GrapheneDB provides hosted Neo4j instances. These guys are awesome! Their service is rock solid. I can't overstate how impressed I am with what they provide (they even allow for running custom server extensions!)
Getting started#
I stumbled acros this node.js hackathon starter template a few months ago. I decided to give it a try for the first time this weekend. It puts together a stack that I'm familiar with: node.js, mongoDB, Express, passport for handling OAuth, Bootstrap and jade. It's a great starter template for, as the name implies, starting hackathon projects.
Graph data model#
Since this project deals with Twitter data, modeling that data as a graph seems intuitive. We're concerned with users, their tweets, and the interactions between users. The data model is pretty simple:
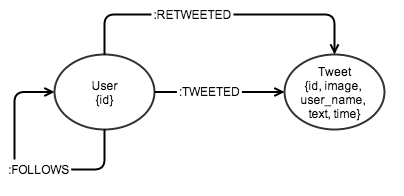
Inserting Twitter Data With py2neo#
Once a user authenticates to our web application and grants us permission to access their Twitter data, we need to access the Twitter API and store the data in Neo4j. We accomplish this with the help of the Python py2neo package.
def cypher_insert(friends, timeline, retweets, ME):
create_user_query = '''MERGE(u:User {id: {me} })'''
create_friend_query = '''MATCH (me:User {id: {me} })
MERGE (u:User {id: {id} })
MERGE (me)-[:FOLLOWS]->(u)'''
add_tweet_query = '''MATCH (u:User {id: {user_id_str}})
MERGE (t:Tweet {id: {id_str}, image: {image},
user_name: {screen_name}, text: {text}, time: {time}})
MERGE (t)<-[:TWEETED {created_at: {time}, time: {id_str}}]-(u)'''
add_retweet_query = '''MATCH (u:User {id: {user_id_str}})
MERGE (t:Tweet {id: {id_str}, image: {image},
user_name: {screen_name}, text: {text}, time: {time}})
MERGE (t)<-[:RETWEETED {created_at: {time}, time: {id_str}}]-(u)'''
# create_user_query
create_me_batch = WriteBatch(graph_db)
create_me_batch.append_cypher(create_user_query, ME)
create_me_batch.run()
print "Beginning user batch"
user_batch = WriteBatch(graph_db)
for user_id in friends['ids']:
user = {}
user['id'] = str(user_id)
user['me'] = ME['me']
print user
user_batch.append_cypher(create_friend_query, user)
user_batch.run()
print "Beginning tweet batch"
tweet_batch = WriteBatch(graph_db)
for tweet in timeline:
tweet_batch.append_cypher(add_tweet_query, tweet)
tweet_batch.run()
print "Beginning retweet batch"
retweet_batch = WriteBatch(graph_db)
for tweet in retweets:
retweet_batch.append_cypher(add_retweet_query, tweet)
retweet_batch.run()
Ranking tweets#
How can we score Tweets to show users their most important Tweets? Users are more likely to be interested in tweets from users they are more similar to and from users they interact with the most. We can calculate metrics to represent these relationships between users, adding an inverse time decay function to ensure that the content at the top of their timeline stays fresh.
Jaccard similarity index#
The Jaccard index allows us to measure similarity between a pair of users. For our purposes this is defined as the intersection of their sets of followers divided by the union of their sets of followers. This results in a score between 0 and 1 representing how "similar" the two users are to each other.
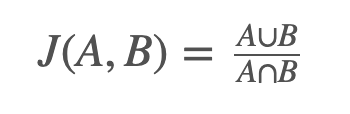
Calculating this in Neo4j Cypher for all users in our database looks like this:
// Jaccard index
MATCH (u1:User), (u2:User) WHERE u1 <> u2
MATCH (u1)-[:FOLLOWS]->(mutual)<-[:FOLLOWS]-(u2) WITH u1, u2, count(mutual) as intersect
MATCH (u1)-[:FOLLOWS]->(u1_f) WITH u1, u2, intersect, collect(DISTINCT u1_f) AS coll1
MATCH (u2)-[:FOLLOWS]->(u2_f) WITH u1, u2, collect(DISTINCT u2_f) AS coll2, coll1, intersect
WITH u1, u2, intersect, coll1, coll2, length(coll1 + filter(x IN coll2 WHERE NOT x IN coll1)) AS union
Interaction metric#
Another important factor to take into account is how often Twitter users are interacting with each other. Users are more likely to be interested in tweets from users they interact with often. To quantify the strength of this relationship for a user pair A,B, we simply divide the number of A,B Twitter interactions by the total number of interactions for user A.
Weighted average#
The similarity score and interaction score are combined using a weighted average. We weight similarity slightly higher than interaction.
Time decay#
To ensure temporal relevence, an inverse time decay function is used to discount tweets according to the amount of time elapsed since the tweet was sent:
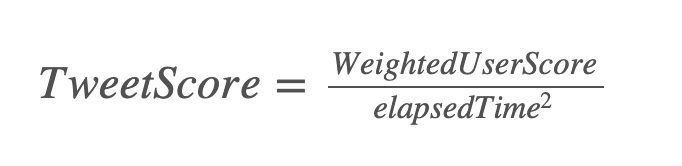
By storing these data and relationships in our Neo4j instance, we simply need to query the database for the highest ranked tweets from our web application and display these to the user.
Extending the Neo4j REST interface#
Neo4j Server provides a REST interface that allows for querying of the database. Neo4j also allows for adding unmanaged server extensions that allow us to extend the built-in REST API and add our own endpoints. We can do this using JAX-RS in Java. In this case, we write a simple server-extension that adds the endpoint /v1/timeline/{user_id} that will execute a Cypher query to return the tweets for the specified user's timeline, ordered by the ranking metric we've defined above.
@Path("/timeline")
public class App
{
private final ExecutionEngine executionEngine;
public App(@Context GraphDatabaseService database) {
this.executionEngine = new ExecutionEngine(database);
}
@GET
@Produces(MediaType.APPLICATION_JSON)
@Path("/{user_id}")
public Response getTimeline(@PathParam("user_id") String user_id){
ArrayList<Object> tweets = new ArrayList<Object>();
Map<String, Object> params = new HashMap<String, Object>();
params.put("user_id", user_id);
String query = "MATCH (u:User {id: {user_id}})\n" +
"MATCH (u)-[s:SIMILAR_TO]->(friend)\n" +
"MATCH (friend)-[:TWEETED]->(tweet) RETURN tweet.time AS created_at, tweet.id AS id_str,\n" +
"tweet.text as text, tweet.user_name as name, tweet.image as profile_image_url,\n" +
"tweet.user_name as screen_name, s.coef as score ORDER BY score DESC";
Iterator<Map<String, Object>> result = executionEngine.execute(query, params).iterator();
while (result.hasNext()) {
Map<String, Object> row = result.next();
Map<String, Object> user = new HashMap<String, Object>();
Map<String, Object> tweet = new HashMap<String, Object>();
user.put("name", row.get("name"));
user.put("screen_name", row.get("screen_name"));
user.put("profile_image_url", row.get("profile_image_url"));
tweet.put("created_at", row.get("created_at"));
tweet.put("id_str", row.get("id_str"));
tweet.put("text", row.get("text"));
tweet.put("promoted", false);
tweet.put("user", user);
tweets.add(tweet);
}
Gson gson = new Gson();
String json = gson.toJson(tweets);
return Response.ok(json, MediaType.APPLICATION_JSON).build();
}
}
Twizzard#
We had the site up and running by the time final presentations were scheduled. In fact, we even had time for a few iterations based on user feedback. We called our web app Twizzard, as in Your Twitter Wizard (but with two z's, like a Tweet Blizzard). It's running now at twizzardapp.com. Sign in with your Twitter account and check it out.
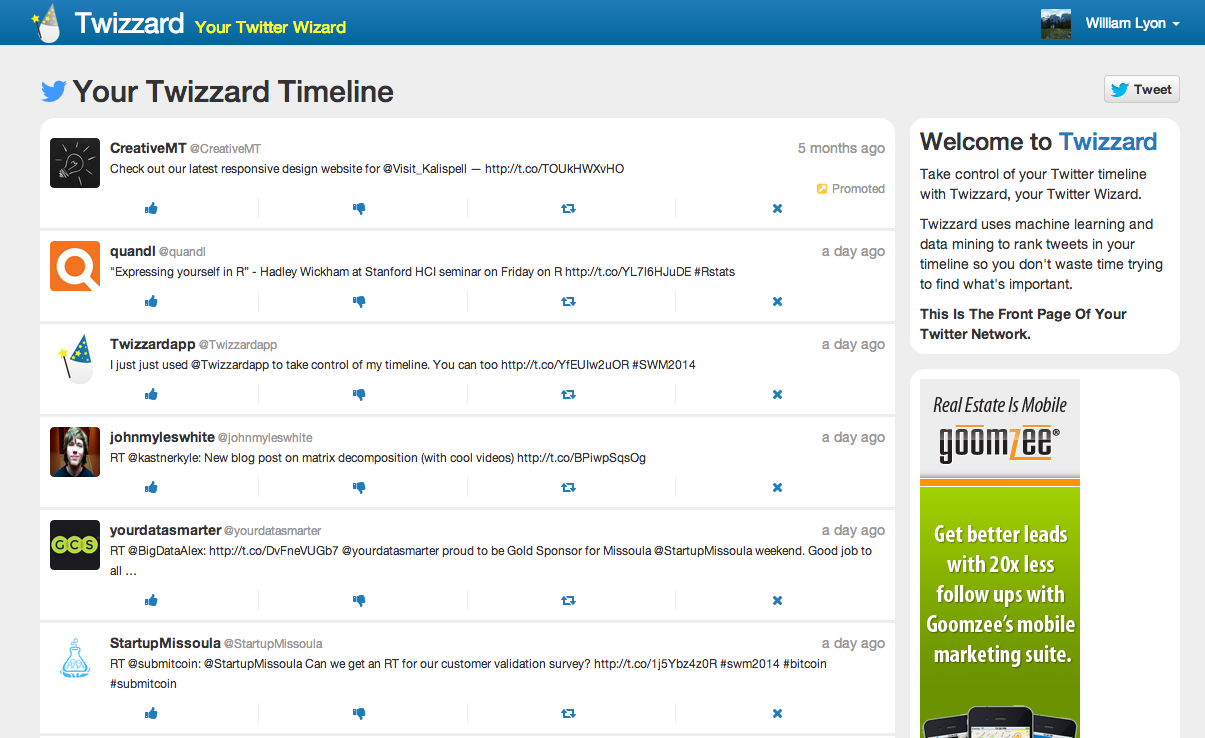
Shout out to my Twizzard teammates @kevshoe and @VisionaryG. It was great fun working with you guys at Startup Weekend Missoula 2014!
Stay Updated
Get notified about new posts and videos